Article
・Kaggleやデータ分析初学者〜中級者向けの実験管理本を執筆しました(共著)。本記事とあわせてご参照くださいませ。
『目指せメダリスト!Kaggle実験管理術 着実にコンペで成果を出すためのノウハウ』

・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
はじめに
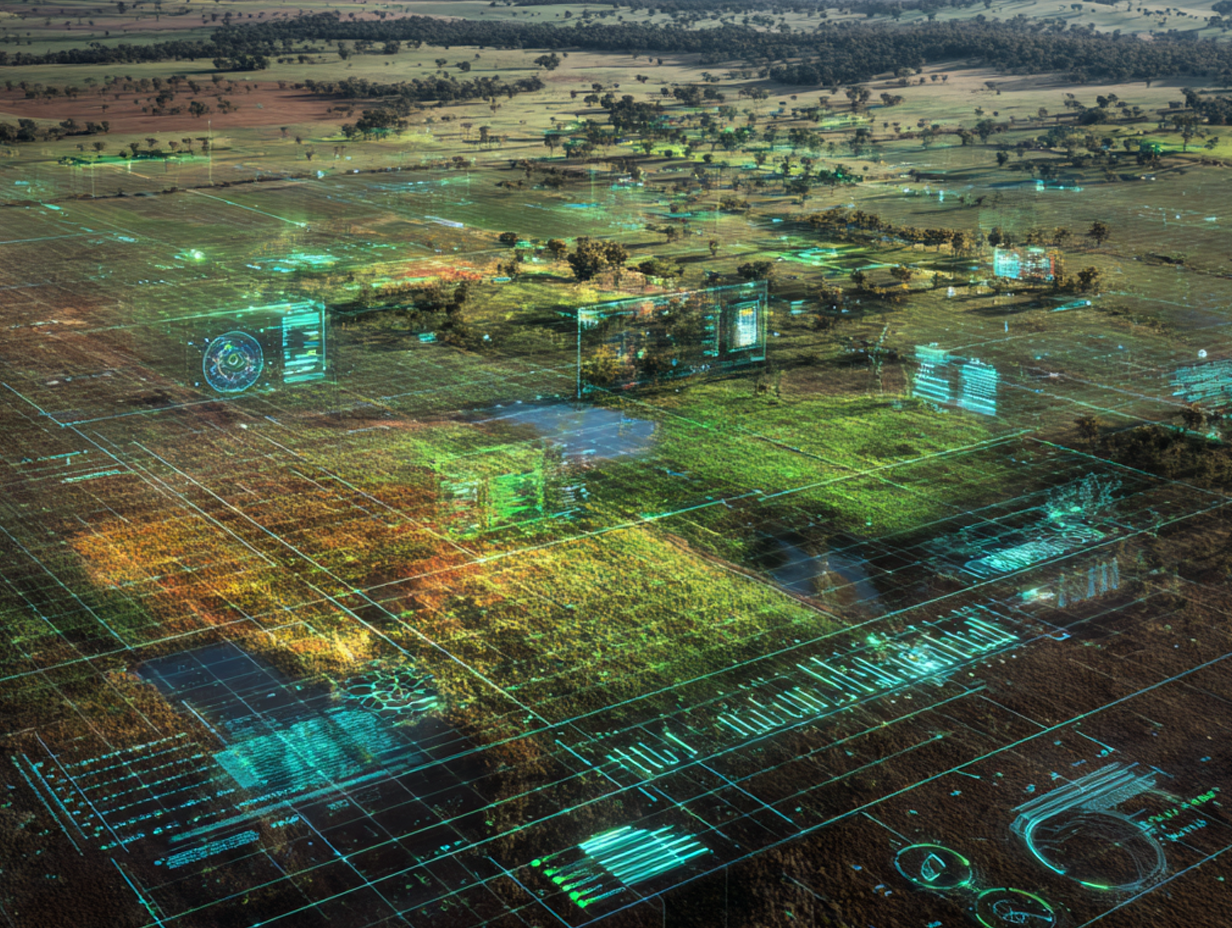
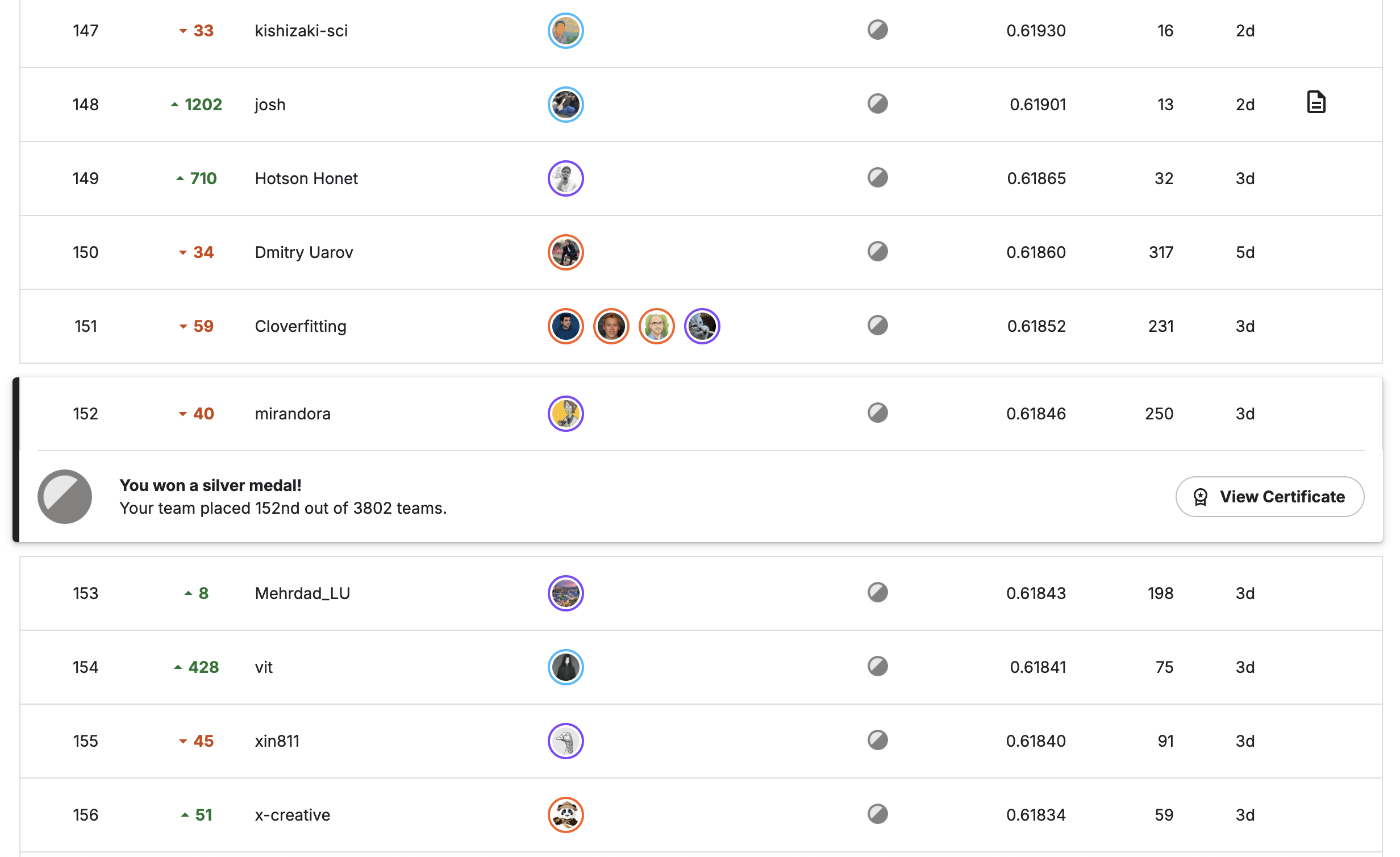
今回はKaggle CSIROコンペあるいは草コンペこと、「CSIRO – Image2Biomass Prediction」の参戦振り返り記事となります。 草の画像から、その画像中のバイオマス量を推定するコンペで、近年では珍しい非常にオーソドックスな画像コンペでした。実際、参加チームは3,803と他コンペよりも多く途中参加も多かった印象です。一方で学習画像データは357枚、テストデータも同等のスモールデータであり、安定的な学習や高精度を出すには不安定、公開codeでDINO v3やSIGLIPを用いた高精度なアプローチが投稿され、そこからの精度改善が難しい点があったり初学者向きなコンペだったのかというと疑問ではあります。最終的には当初discussionで予想されていたほどのbig shakeは無く、public/privateのLBはかなり相関がとれていたようでした。結果public112位、private152位でsilverメダルとなりました。本稿ではコンペの概要および上位解法などを振り返っていきたいと思います。
| (1) CSIROコンペの概要
このコンペの目的は、下記のようなオーストラリアの牧草地の画像からその画像範囲のバイオマスを正確に推定するAIモデルを構築することでした。

コンペでは以下のデータが提供されました。ただし一部のデータはtrainデータのみに含まれていました。
・画像データ: 牧草地を真上から撮影した画像。
・メタデータ/補助データ(※trainデータのみ提供)
- NDVI (正規化植生指標): 植物の健康状態や密度を示す指標。
- 草丈 (Height): 牧草の高さ。
- 日付:撮影・データ計測された日付
- 地域:オーストラリアの4つの州のどこか
- 草種:Cloverなどの草種
・目的変数 (ターゲット): 以下の5つのコンポーネントの重量(グラム)
- Dry green vegetation (excluding clover): クローバー以外の乾燥緑色植生
- Dry dead material: 乾燥した枯死材
- Dry clover biomass: 乾燥クローバー
- Green dry matter (GDM): 緑色乾燥物(1と3の合計)
- Total dry biomass: 総乾燥バイオマス(すべての合計)
評価指標評価には Weighted R2 (重み付き決定係数) が採用されました。各ターゲットを個別に計算して平均するのではなく、ターゲットは対数変換された状態で、すべての画像とターゲットのペアを一つのリストにし、以下の重みを掛けて評価されました。
– Total dry biomass: 0.5(最も重要視される)
– GDM: 0.2
– その他の3種: 各0.1
コンペ中、meta社のDINOv2,DINOv3という強力なセグメンテーション能力を持つモデルをバッグボーンに用いたアプローチが公開され、参加者の多くがこれらを利用し工夫を加えていました。他にSigLIPを用いてターゲットと関連するプロンプトと画像の関係を特徴量としてそれらをgbt系モデルで学習するというアプローチも公開され、公開notebookの多くはこのアンサンブルでした。
| (2) 本コンペの取り組み
本コンペの私のアプローチは下記のようなものでした。
6つの異なるDINOv2,DINOv3モデルとSigLIPのアンサンブル
– DINOv2:別の公開データセット(irishデータ)のうち本コンペの画像と類似度やターゲットが近いものを学習に追加
– DINOv2:cvの切り方を上記のモデル予測の予実差を用いてStratified
– DINOv2:NDVI * heightの値を補助タスクとして追加
– DINOv3:NDVI * heightの値を補助タスクとして追加したDINOv3バージョン
– DINOv3:Ema callback追加
– DINOv3:SE blockを追加
上記にさらにシンプルなSigLIPのモデルを加えています。
後処理
– State予測による後処理
一部のStateでは特定の草種が0になることが多かったりしたため、Stateを用いた後処理を加えました。
Stateは学習時のみに与えられるデータですが、90%の精度で予測可能だったため、testデータでも画像から予測して用いていました。
– 誤差最小化による最適化
公開notebookの多くは、clover, total, gdmの3種のターゲットを予測した上で、green, deadを物理制約(「Dry_Green_g = GDM_g – Dry_Clover_g」、「Dry_Dead_g = Dry_Total_g – GDM_g」)から求めていました。
しかしこれだと予測誤差が特定のターゲットに寄ってしまうことを懸念し、誤差を最小にする最適化ができないかと思いました。
上記2つを合わせて具体的には下記のような処理を加えていました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
def solve_biomass_with_state_logic(clover_pred, total_pred, gdm_pred, state): """ State特性と数学的制約を同時に解決する最適化 x: [Clover(0), Dead(1), Green(2), Total(3), GDM(4)] """ # 初期値(非負にクリップ) c_init = max(0.0, clover_pred) t_init = max(0.0, total_pred) g_init = max(0.0, gdm_pred) gr_init = max(0.0, g_init - c_init) d_init = max(0.0, t_init - g_init) x0 = np.array([c_init, d_init, gr_init, t_init, g_init]) # 目的関数: 元の3つの予測値(C, T, G)との乖離を最小化 # 重みはコンペ評価を考慮し Total(1.0) > GDM(0.8) > Clover(0.5) と設定 weights = {0: 0.5, 3: 1.0, 4: 0.8} def objective(x): return (weights[0] * (x[0] - clover_pred)**2 + weights[3] * (x[3] - total_pred)**2 + weights[4] * (x[4] - gdm_pred)**2) # 数学的整合性(等式制約) cons = [ {'type': 'eq', 'fun': lambda x: x[4] - (x[0] + x[2])}, # GDM = Clover + Green {'type': 'eq', 'fun': lambda x: x[3] - (x[4] + x[1])}, # Total = GDM + Dead ] # 境界条件 (Bounds) の初期設定: すべて 0 以上 # (min, max) for [Clover, Dead, Green, Total, GDM] bnds = [(0, None), (0, None), (0, None), (0, None), (0, None)] # --- Stateに基づく条件付き制約 --- # NSW: Clover < 10 の場合は Clover を 0 に強制(境界条件で縛る) if state == "NSW" and c_init < 10: bnds[0] = (0, 0) # WA: Dead はないので 0 に強制 # これにより、Optimizerは「Total = GDM」を満たしつつ、 # 元のTotalとGDMの「中間(平均に近い値)」を自動的に探索。 if state == "WA": bnds[1] = (0, 0) # 最適化実行 (SLSQP法) res = minimize(objective, x0, method='SLSQP', bounds=bnds, constraints=cons, tol=1e-6) if res.success: return res.x else: # 万が一失敗した場合は、最小限のクリップを施した初期値を返す return x0 |
モデルによって予測幅が異なるため、それらを単純にアンサンブルするよりも、いちばん精度の良いモデルを基準に、順位を並び替えてそれをアンサンブルするというアプローチにしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
def rank_average_ensemble_final(sub_base, sub_to_blend, target_weights=None, default_weight=0.8): """ 1. 各ターゲットごとに設定された重み(weight_base)を取得 2. 各ターゲットごとに順位(Rank)を計算 3. 順位をターゲット別の重みで平均 4. 平均順位を sub_base の実際の値にマッピングする Parameters: ----------- target_weights : dict {'Dry_Clover_g': 0.7, 'Dry_Total_g': 0.9, ...} のような形式 """ sub_base = sub_base.copy() sub_to_blend = sub_to_blend.copy() # ターゲット名の抽出 sub_base['target_type'] = sub_base['sample_id'].str.split('__').str[-1] sub_to_blend['target_type'] = sub_to_blend['sample_id'].str.split('__').str[-1] target_types = sub_base['target_type'].unique() final_results = [] for t_type in target_types: # --- Step 0: ターゲットごとに抽出し、IDで確実に紐付ける --- s1 = sub_base.loc[sub_base['target_type'] == t_type, ['sample_id', 'target']].copy() s2 = sub_to_blend.loc[sub_to_blend['target_type'] == t_type, ['sample_id', 'target']].copy() m = pd.merge(s1, s2, on='sample_id', suffixes=('_base', '_blend')) if len(m) == 0: continue # --- Step 1: ターゲットごとの重みを設定 --- # 辞書に指定がない場合は default_weight を使用 w1 = target_weights.get(t_type, default_weight) if target_weights else default_weight w2 = 1.0 - w1 # --- Step 2: 順位計算と重み付き平均 --- r1 = m['target_base'].rank(pct=True) r2 = m['target_blend'].rank(pct=True) m['avg_rank'] = r1 * w1 + r2 * w2 # --- Step 3: マッピング(sub_baseの分布を維持) --- sorted_values = np.sort(m['target_base'].values) n = len(sorted_values) idx = (m['avg_rank'] * (n - 1)).round().astype(int) m['target'] = sorted_values[idx] final_results.append(m[['sample_id', 'target']]) return pd.concat(final_results).reset_index(drop=True) |
| (3) 上位ソリューション
上位陣のソリューションを分析するとモデルは同じでも、多くの私が実行していない(あるいは試したものの諦めた)アプローチがありました。
[各チームのアプローチ] ※解釈違いあるかもしれません。詳細は下記のチーム名からのリンクをご確認ください。
| 順位・チーム名 | アプローチの要約 | 自分との差分 |
|---|---|---|
1位卷不动了
|
7つの区間の分類タスクにしたモデルを追加 | 分類タスクにしたモデルは未着手 |
| 入力画像サイズを1024pxに拡大 | DINOv2で512以降は精度改善できず断念 | |
| 2段階のトレーニング(Fine-tuning戦略) | 2段階学習は未着手 | |
| TTT (Test Time Training) | SigLIPで試したが改善せず断念、DINOでは未試行 | |
2位dino series
|
Qwenを用いた合成データセット作成(LabelにはPseudo Labeling) | Nano bananaを用いた修正データセットを作成したものの精度が下がったため断念(合成データへのPseudo Labelingは未着手) |
| 入力画像サイズを2048*1024,1024*1024pxの2種類に | DINOv2で512以降は精度改善できず断念 | |
| 単純な回帰ではなく密度推定 | 密度推定は未着手 | |
| Stateごとのターゲットのスケーリングの微調整 | ターゲットごとに微調整を試みるもうまくいかず断念(Stateごとは未着手) | |
3位embee
|
mixupおよび画像を複数タイルに分割して並び替えた拡張 | どちらも試したものの精度悪化したため断念 |
4位yanqiangmiffy
|
学習画像に含まれているオレンジ色の日付タイムスタンプを画像処理で除去 | nano bananaで日付除去した画像を生成したものの精度が悪化したため断念 |
| 最初の15epochはランダムに選ばれた拡張を適用、残りは拡張オフ | epochごとの拡張適用は未着手 | |
| 左右の分割及び画像全体の3入力 | 精度が悪化したため断念 | |
| StateごとのターゲットのClip | Stateごと、ターゲットごと含めて未着手 |
上記全くできていなかったもののあれば、部分的に取り組んでいたものもあります。しかし精度改善につながらず断念したものの多くは、あと一歩パラメータ探索が足りないか、そもそもこうするべき、という仮説が足りていませんでした。得てしてコンペ後半は打ち手がだんだんなくなりがちですが、断念したアプローチの中にヒントがあることはよくある話です。今後はNotionなどで実験管理する際に、アプローチとは別にパラメータ探索などの着手/未着手ステータスが一目でわかるように整理しようと思いました。
| (4) 反省・今後に向けて
本コンペの敗因はテクニカルなこと以前に下記の2点に集約されます。
・最後までモチベーションを持続できなかった
これが一番の敗因です。「絶対精度が改善するだろう」と思ったいくつかのアプローチを中盤〜終盤に外した時、「なんだこのコンペ。データも少ないし、どうせshakeするコンペなのだろう」と最後1週間は、ほぼ惰性のsubで終わってしまいました。しかし最終的にpublic/privateの相関はとれており、LBの改善の工夫を続けていれば、もう少し良い結果を得ることができたはずです。データ数が少ない、コンペ設計がおかしい、様々な言い訳がKaggleに参加していると出てきます。でも、それがKaggleではないでしょうか。その言い訳を正当化したいなら、もっと初期に撤退ラインはあったはずです。近年では一番中途半端な参加の仕方をしてしまいました。取り組み方もClaude CodeでのEDAやuv、環境構築などで今回のコンペで初めて試したアプローチはあり学びはありましたが、もしスコアにこだわらないならもっとそれに徹しても良かったかと思います。総じて冷笑的にやるKaggleほど意味のないものはないと痛感しました。
・マジックや画期的なアプローチがあると期待してベーシックな改善をないがしろにしてしまった
Kaggleでは上位陣は自分と全く異なる何か特別なことをしているのではないかと勘ぐり、さまざまなアプローチに発散しがちです。それ自体は悪いことではないのですが、一つのアイデアに対する執着心が足りなかったと思います。そのアプローチは本当に棄却できるほどさまざまなパラメータや実装を試したかという姿勢が大事だと思います。またそもそも予測モデルの学習のさせ方など細かいチューニングで大きな差がでることがあります。そういった地道な工夫をコツコツと十分にできなかった点が大きな反省です。
端的にいうと、その時々で、自分がやっているアプローチでのベストをまず出し切る、ということを徹底するべきだと思いました。これはもしかしたらKaggle以外でも重要なことかもしれません。
本記事執筆時点でsilver10枚、bronze9枚。Silverコレクターの道は続きます。以上、CSIROコンペの振り返りとなります。
関連記事:






人気記事: