Article

・Kaggleやデータ分析初学者向けのチュートリアル解説本を執筆しました。本記事とあわせてご参照くださいませ。
『Pythonで動かして学ぶ!Kaggleデータ分析入門』

・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
はじめに
今回はKaggleMLBコンペこと、「MLB Player Digital Engagement Forecasting」の参戦振り返り記事となります。野球のstatsデータとソーシャルデータの組み合わせというユニークな問題設計が興味深く、時系列データに対するNNを含めたアプローチの学習というモチベーションで参加いたしました。結果はprivate LB26位でsilverとなりました。本記事では本コンペの取り組みやscore推移、上位ソリューションを振り返っていきます。
※ちなみにサムネイル画像は、シアトルで現地観戦したマリナーズ戦の写真

| (1) MLBコンペの概要
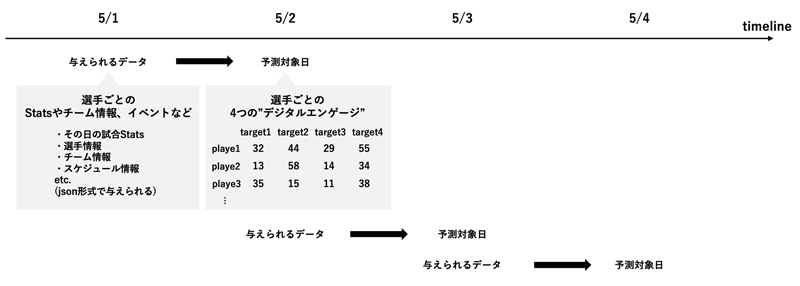
本コンペは、野球選手ごとの日別のプレイstatsデータが与えられ、その翌日の選手ごとの4つのソーシャルエンゲージメント(これが何であるかは明言されていませんが、いいねや拡散などに関するものを相対化したもの。0〜100の値)を予測するというものでした。どのような活躍をした選手がファンの話題になりやすいかという分析をすることになります。評価指標はmean column-wise mean absolute error (MCMAE)でした。
説明変数としてのプレーヤーごとの試合ごとのstatsデータは下記のようなものがJSON形式で日別ごとに行にまとめて与えられました。
| train.csv | trainデータ(この中にJSON形式で日別のtargetや試合ごとの選手のstatsが含まれる) |
| example_test.csv | サンプルtestデータ |
| example_sample_submission.csv | サンプルsubmit |
| awards.csv | アワードに関する情報(アワードごとにどの選手が受賞したかなど) |
| players.csv | すべてのMLB選手に関する情報(誕生日や出身地、ポジションなど) |
| seasons.csv | シーズンに関する情報(シーズンIDごとに何日から何日まで開催されるかなど) |
| teams.csv | すべてのMLBのチームに関する情報(チーム名、ホームの場所、リーグIDなど) |
本コンペは2stage制のコードコンペとなります。与えられた期間のデータでモデルを作成し、最終的なprivate順位はコンペ終了時点から将来のデータに対して予測した結果が用いられます。そのためモデルが未知のデータに対してもエラーなく実行できるかが求められます。(実際それなりのチーム数が実行エラーでprivateでは脱落となりました)
なお私は小学生時代にソフトボールをやっていましたため野球自体の基本的なルールは理解しているつもりですが、プロ野球の観戦習慣がなくMLBの試合運営スケジュールやレギュレーションがわからず、選手もごく一部の有名選手しかわかりません。例えば「MLBは毎日試合があるのか」「MLBはレギュラーシーズンとポストシーズンがあるのか」「誰がスタープレイヤーか」「どのチームとどのチームがライバル関係か。どのチームが強豪か」などが全くわかりませんでした。この点は本コンペで苦労した点のひとつです。※私はサッカーファンであり、サッカーは現地観戦のために海外に行くこともままあります。
| (2) 本コンペの取り組み
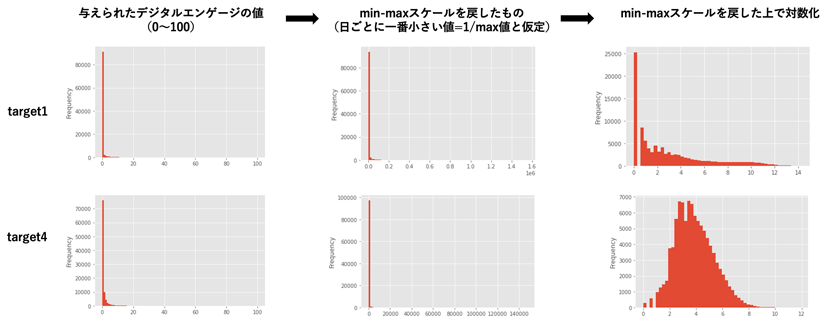
まずは目的変数であるデジタルエンゲージメントとは結局何なのか(いいねなのかフォローなのかetc)を特定することや、targetを変換すると予測しやすくなるか考えました。具体的にはmin-maxによる変換、対数化などです。しかし、結局targetの変換は予測精度が悪くなり断念しました。(が、min-maxはせずとも対数化はするべきでした)
次に時系列データであることから、年単位・月単位など様々なスパンでの統計量、直近の増減傾向を算出しました。このような時系列性はGRUやtransformerなどの場合、NNにわからせるという手もあったかもしれません。
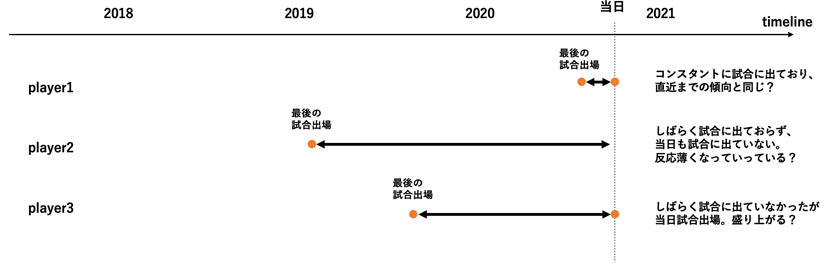
特徴量は、「チーム間でのライバル関係のフラグ(通常の試合よりもダービーのほうがSNS上で盛り上がることを想定)」、「各プレイヤーにとってその日が最後の出場から何日経過しているか(デジタルエンゲージを考えたときに、怪我やトラブルなどで試合に出ていない期間が長くなると徐々に忘れられていきSNSの反応が小さくなっていくのではと仮定。逆に久々の出場は盛り上がることも考えられる)」といったものを追加しました。
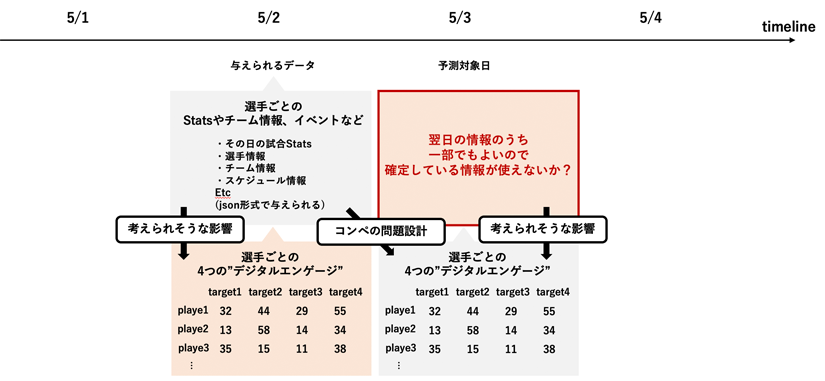
また今回の問題設計は「ある日の試合情報をもとに次の日の選手ごとのデジタルエンゲージメントを予測する」というものでしたが、SNSの盛り上がりなどを考えるともちろん試合当日のほうが盛り上がることが考えられますので、「各選手ごとに次の日に試合があるか」を特徴量として追加しました。
あとはtarget自体のlag特徴量も非常に強力でしたが、予測期間においてすべて使用できるわけではなく、予測結果自体をリカーシブに入力したり、lagを使用するもの・使用しないものでモデルを分けるなどの工夫をしました。(この点はさらに踏み込んだ活用が考えられ次の章で後述します)
最終的なパイプラインは下記のようになりました。実装においては特徴量生成の全ての処理において例外処理をいれており予期せぬ値やそもそも値が取得出来ないときにエラーとならないよう注意しました。
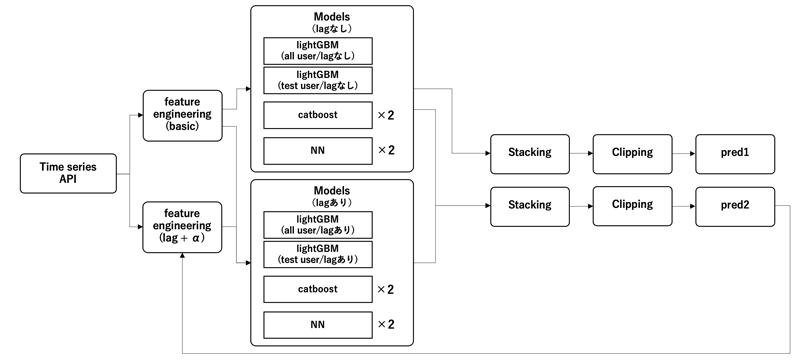
| (3) 上位ソリューション
公開されている上位陣のソリューションをみた限り、下記が主要な取り組みだったようです。
・(targetの値はtrainデータの最後の日までしか利用できないことを考慮し、)lag特徴量は3日前、7日前、30日前など様々なスパンで入力
・targetはlog(1+x)で対数化、あるいは二重平方根でスケール化
・モデルは1dCNN(moaコンペ2位のモデル)、GRU、lgb(regression_l1, regression_l2といった違いやtargetを変換したもの/しないものなど様々なバリエーション)
・ドメイン知識に基づく特徴量(SNS投稿に関連しそうな、サヨナラヒット、ホームランレースのランキング、ノーヒッター、防御率、防御率のランキングetc)
・1日の試合やイベントの数、イベントレベルのメタ特徴量
・time series apiのエミュレーターを使用して、ローカルでデバッグ(エラーのない処理を実装するために重要)
・様々な関数で例外処理をキャッチし欠損値をデフォルト値で置き換える
上位ソリューションは細かい点で丁寧で、一つ一つのアプローチの細部で差がついたように思います。またcodeコンペやtime series apiによるコンペに対してローカルで適切なデバッグができるパイプラインを構築することが非常に重要であると感じました。ドメイン知識についてはもっとリサーチできたはずだった点は反省です。
| (4) おわりに
残念ながらgoldには届かなかったものの、コンペのモチーフは非常に面白く大変楽しみながら取り組むことができました。
細かな点はありつつ、GBTでベースラインを構築しつつGRUなど様々なNNアプローチに取り組んだものの十分な精度を出すことができなかった点は上位と差がついた要因のひとつであると思います。この点はコンペ終了後に復習してキャッチアップしなければならないと感じた点です。
次回は是非サッカーを題材にしたコンペでの開催を心待ちにしております。
関連記事:




人気記事: