Article

いよいよ12月も下旬に入り、
世間はクリスマスに向けての3連休に、華やいだ様子が見られます。
カップルがきらびやかな街中のイルミネーションを楽しむ中、
データサイエンティスト諸君は、いつもと変わらずギラついたPCのターミナル画面をご覧になっていることでしょう。
しかし、この3連休くらいは、年末年始の何かとお金がいりような時期の軍資金を確保すべく、
普段の日常業務と離れて、有馬記念にデータサイエンスで挑んでいきたいと思います。
ちなみに私は競馬をやったことがございません。
しかし、任天堂の魅力的なゲームソフト発売ラッシュに、手段を選んでいられないくらい切羽詰まっているのです。
まあ、データサイエンスと気合(チャクラ)があればなんとかなるでしょう。では、やっていきましょう。
(1) そもそも有馬記念とは
(2) 競馬におけるデータサイエンスの取り組み
(3) 今回用いる競馬データセット
(4) 有馬記念予想モデル
(5) 当日の有馬記念の様子(※2018/12/24追記)
(6) 結果(※2018/12/24追記)
| (1) そもそも有馬記念とは
競馬に疎い私でも、なんとなく、年末に行われる大きな競馬レース、として有馬記念は認識しております。
ざっと、JRAの公式ページや、wikipediaを参照しますと、
「1956年創設、毎年12月下旬に中山競馬場で開催される、名実ともに日本国内の最大級のレース」とのことでして、
その最大級たるゆえんは、
・国際競馬統括機関連盟が公表の世界のトップ100GIレースランキングにおいて14位
※ちなみに、天皇賞、ジャパンカップは12位。世界1位はフランスの凱旋門賞。
・日本競馬における1レースとしての売上高が最高。
・賞金は、日本競馬最高額である1着3億円。
であるようです。すごいじゃん(小並感)
出走馬は、条件をみたした、馬のうち、ファン投票上位10頭、
外国馬、および地方競馬所属馬のうち、賞金成績が多い馬が出場、とのことです。
ちなみに、今年の2018年第63回グランプリは、12/23(日)15時25分から開催されます。
| (2) 競馬におけるデータサイエンスの取り組み
競馬における、市井のデータサイエンスの取り組みは枚挙にいとまがなく、
調べれば調べるほど、多くの事例が出てきます。
「大井競馬で帝王賞を機械学習で当てた話」
今年の夏ころに話題になっていた、帝王賞の1位を当てた記事。
データは南関東4競馬場公式サイトからのクローリング、
対象データは2018年の大井競馬場のレース、
目的は順位予想、にしているようです。
手法はMLP(DeepLearningの一種)を用いてるようです。
「頭数」「獲得賞金金額」「順位」「レースの長さ」「人気」「体重」「タイム」「芝状態」など、9つの特徴量を用いられておりました。
「競馬の予測をガチでやってみた」
2016年頃の記事ですが、今見ても読み応えがある記事です。
データはnetkeiba.comをスクレイピングされております。
この記事では、目的を、「1位か否か」にしているようです。
なぜなら
“競馬ではレースの途中で騎手が「このままでは上位になれないな」と気付いたとき、
馬を無駄に疲れさせないためにあえて遅く走らせることがあるのだそうだ
(競馬は着順が上位じゃないと賞金が貰えないため)。
(参考:”Identifying winners of competitive events: A SVM-based classification model for horserace prediction)”
とのことです。知らなかった、。
もう1点、本記事で勉強になったのは、ベンチマークとして、
「人気(オッズ)からの勝率」を用いており、それをいかに上回るか、としていることです。
最終的には「人気」も変数に用いておりますが、基準として、たしかにそれをどれだけ上回ったかは重要ですね。
なお、記事中で、競馬予測のためのデータサイエンスの本も紹介されております。
まだ読んでませんが、チェックしておこうと思います。
「AIが競馬予想で回収率180%突破の快挙! 『電脳賞』優勝のITエンジニアが語る戦略が鮮やかすぎて目からウロコ」
ドワンゴが主催する競馬予想プログラミングコンテスト「電脳賞」の
優勝チームおよびパーフェクト的中率ちー雨へのインタビュー記事です。
上記2記事と異なり、詳細なコードなどが紹介されているわけではないですが、
非常に読み応えがあります。
電脳賞が、回収率が高いチームが評価されるため、
いかに「1番人気が1位になりづらいレース」を予想するか、について述べられております。
その他、モデルの生成にあたって、
“はじめはオッズ、馬体重、タイムなどあらゆるパラメーターを入れていたんですが、
そこから競馬を徐々に理解していくにつれて不必要なものを引いていったんですね。
その結果、的中率が上がっていきました。”
というあたりは非常に参考になります。
その他、プロアマ含めて様々なデータサイエンスを用いた競馬に対する取り組みがあります。
が、無限に先行事例が出てくるため、どこかで読むのを切り上げないと、
有馬記念に間に合わないどころか、年越ししてしまうどころか、
気づいたら、シンギュラリティーが到来して、人間が馬の順位を予想するどころか、
AIが馬車馬のように働く人間を予想する世界が到来してしまいます。
| (3) 今回用いる競馬データセット
今回、ふたつのデータソースを用いてスクレイピングしました。
・JRA公式サイト:レース成績データ
JRA公式サイトには、有馬記念はもちろん、過去の様々なレースの成績データを見ることができます。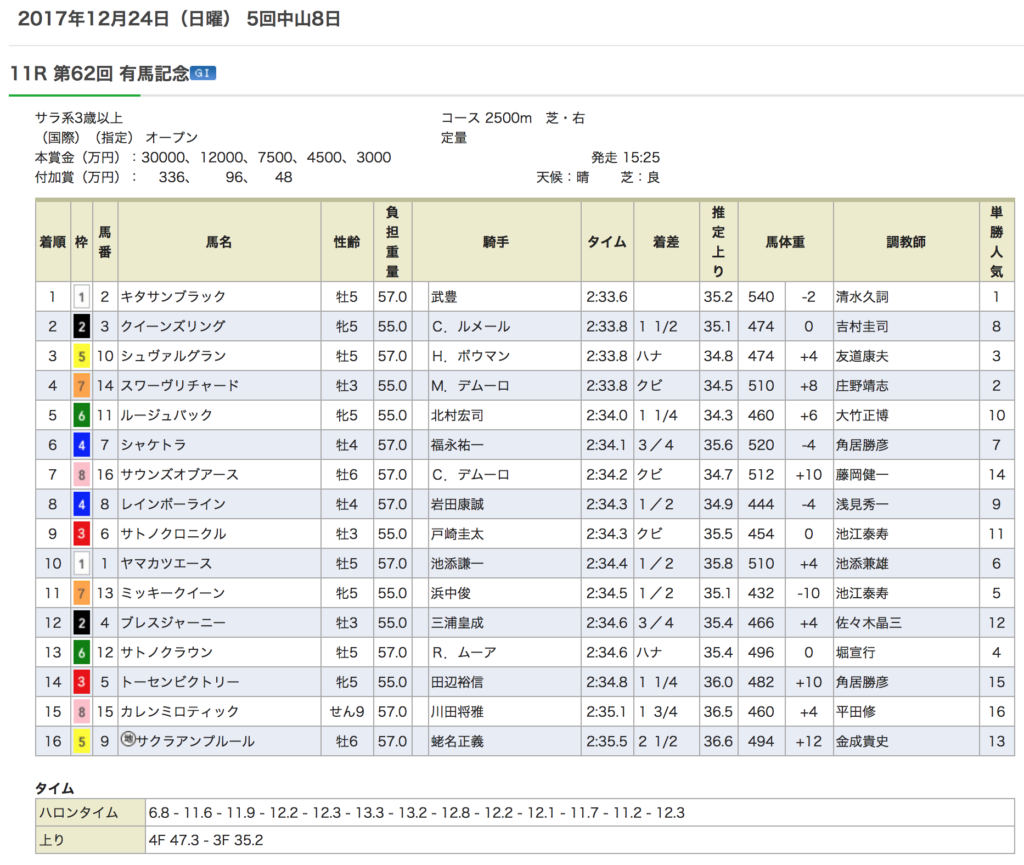
まずは、ここから、2010年以降の有馬記念のデータ、および2017年、2018年有馬記念に出走した馬が出たレース、
の成績データを収集します。
合計56レースのデータを収集しました。
・netkeiba.com:データベース
国内最大級の競馬情報サイトであるnetkeibaからは、
競走馬、騎手、調教師、などの様々なデータを見ることができます。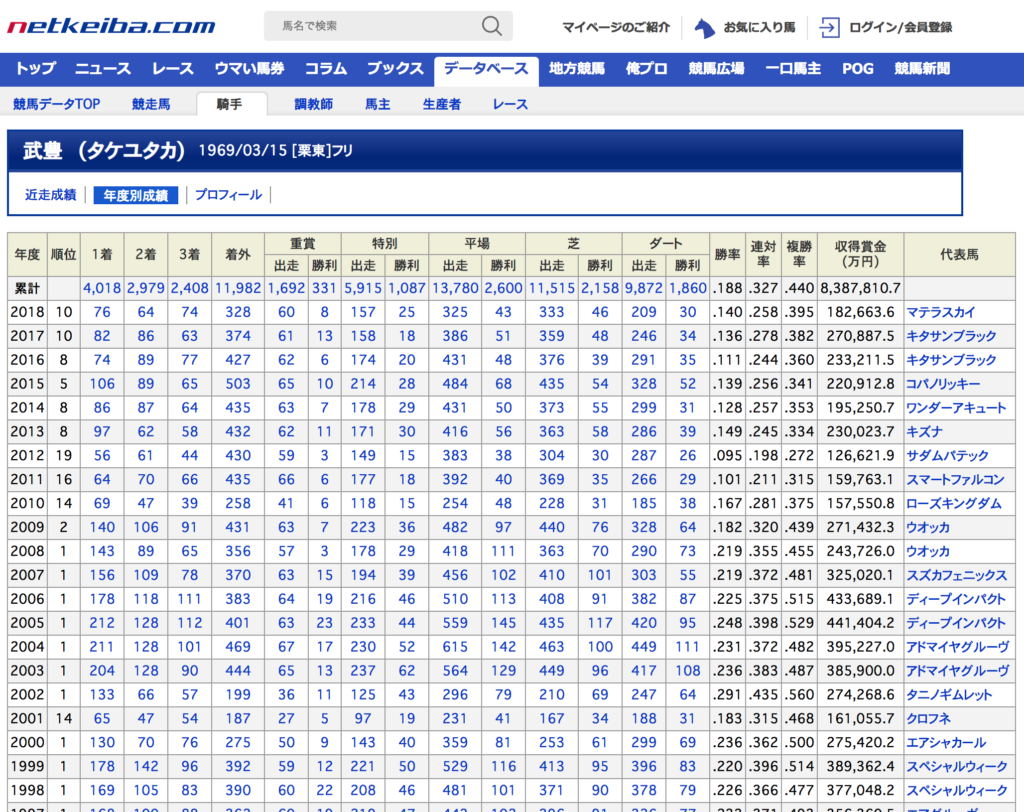
こちらから、先程JRA公式サイトから収集したレースに含まれる、
全騎手、調教師の年別実績データ・プロフィールデータ(騎手の身長、体重、など)を収集します。
結果、100人の騎手、147人の調教師のデータが集まりました。
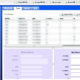
「レース成績データテーブル」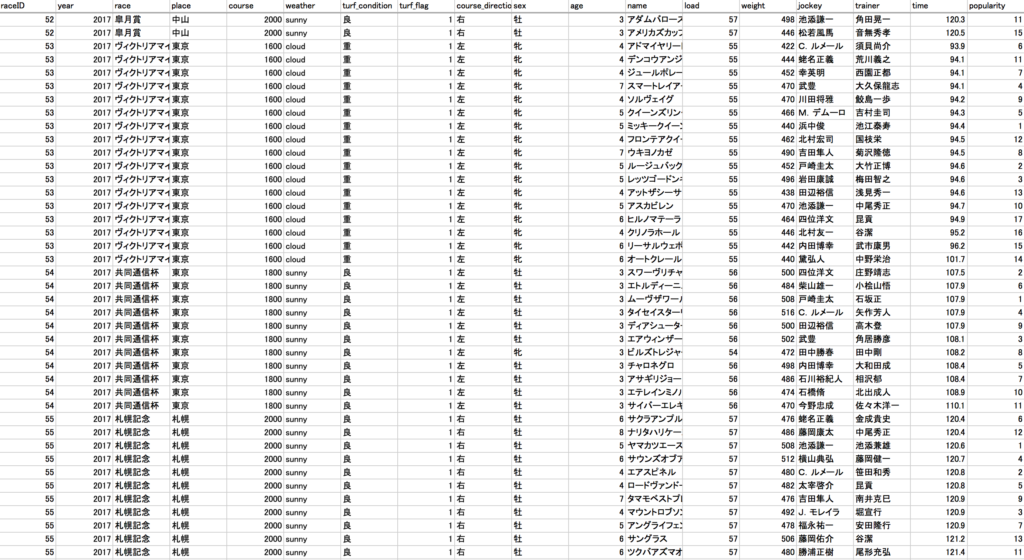
「騎手データテーブル」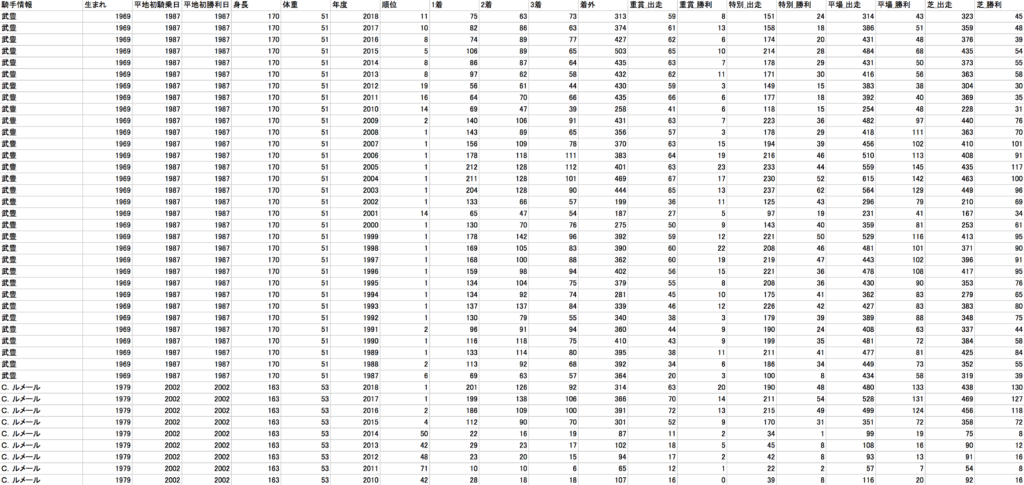
「調教師データテーブル」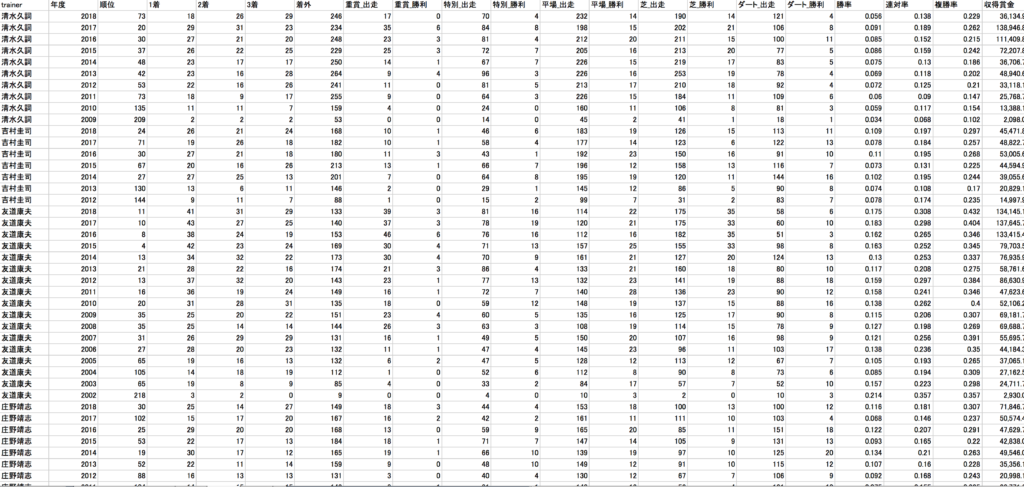
レース成績データテーブルの騎手・調教師で紐づけて、
上記の3つのデータを統合して、1つのデータテーブルにします。
また、各種前処理をこの段階で行っておきます。
最終的に下記のような55項目をもつデータセットを生成しました。
| raceID | レースID(raceID=0が、2018年有馬記念のレース) |
| year | 該当レコードのレース実施年 |
| race_arima_flag | 該当レコードのレースが有馬記念かどうかのflag(1が有馬記念、0が有馬記念以外) |
| nakayama | 中山競馬場 |
| tokyo | 東京競馬場 |
| kyoto | 京都競馬場 |
| hanshin | 阪神競馬場 |
| niigata | 新潟競馬場 |
| hakodate | 函館競馬場 |
| sapporo | 札幌競馬場 |
| fukushima | 福島競馬場 |
| chukyo | 中京競馬場 |
| course | レースの距離 |
| weather | 天気(1:晴、0:曇、-1:雨) |
| turf_condition | 芝のコンディション(1:良、0:重、-1:不良) |
| course_direction_right | 該当レコードのレースが右回りか左回りか(1:右、0:左) |
| male | 牡 |
| female | 牝 ※male、femaleともに0は、「せん(※去勢した牡)」 |
| age | 馬の年齢 |
| load | 馬の該当レコードのレースにおける重荷 |
| weight | 馬の体重 |
| time | 該当レコードのレースのタイム |
| race_rank | 該当レースの実際の順位 |
| popularity | 該当レコードのraceIDにおける人気 |
| jk_age | 騎手の年齢 |
| jk_ride_his | 騎手の初レースからの年数 |
| jk_win_his | 騎手の初レース勝利からの年数 |
| jk_height | 騎手の身長 |
| jk_weight | 騎手の体重 |
| jk_rank | 騎手のその年の順位 |
| jk_1st_rank | 騎手のその年の1位になったレース数 |
| jk_2nd_rank | 騎手のその年の2位になったレース数 |
| jk_3rd_rank | 騎手のその年の3位になったレース数 |
| jk_other_rank | 騎手のその年の4位以下になったレース数 |
| jk_1st_rank_rate | 騎手のその年の1位になったレース割合 |
| jk_2nd_rank_rate | 騎手のその年の2位になったレース割合 |
| jk_3rd_rank_rate | 騎手のその年の3位になったレース割合 |
| jk_turf_run | 騎手のその年の芝のレース数 |
| jk_turf_win | 騎手のその年の芝のレース勝利数 |
| jk_turf_win_rate | 騎手のその年の芝のレース勝利割合 |
| jk_prize | 騎手のその年の獲得賞金 |
| tr_rank | 調教師のその年の順位 |
| tr_1st_rank | 調教師(が担当する馬)のその年の1位になったレース数 |
| tr_2nd_rank | 調教師(が担当する馬)のその年の2位になったレース数 |
| tr_3rd_rank | 調教師(が担当する馬)のその年の3位になったレース数 |
| tr_other_rank | 調教師(が担当する馬)のその年の4位以下になったレース数 |
| tr_1st_rank_rate | 調教師(が担当する馬)のその年の1位になったレース割合 |
| tr_2nd_rank_rate | 調教師(が担当する馬)のその年の2位になったレース割合 |
| tr_3rd_rank_rate | 調教師(が担当する馬)のその年の3位になったレース割合 |
| tr_turf_run | 調教師(が担当する馬)のその年の芝のレース数 |
| tr_turf_win | 調教師(が担当する馬)のその年の芝のレース勝利数 |
| tr_turf_win_rate | 調教師(が担当する馬)のその年の芝のレース勝利割合 |
| tr_prize | 調教師(が担当する馬)のその年の獲得賞金 |
| all_race_rate | 馬の全レースの平均ペース |
| same_race_rate | 馬の有馬記念と同水準のレース(2400m or 2500mレース)の平均ペース |
では、いよいよ分析していきます。
| (4) 有馬記念予想モデル
まずは、ざっとデータ探索していきます。
今回、わざわざデータ分析することで、人気(オッズ)で買うよりも正解率を高くすることが目的となります。
そこで、人気は、実際の順位と関係しているのか、をまずは見てみます。
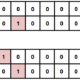
まずは人気と順位相関係数は、0.61となりました。なかなか高いですね。
下記が詳細な、人気(縦)ごとの実際の順位(横)のクロス表となります。
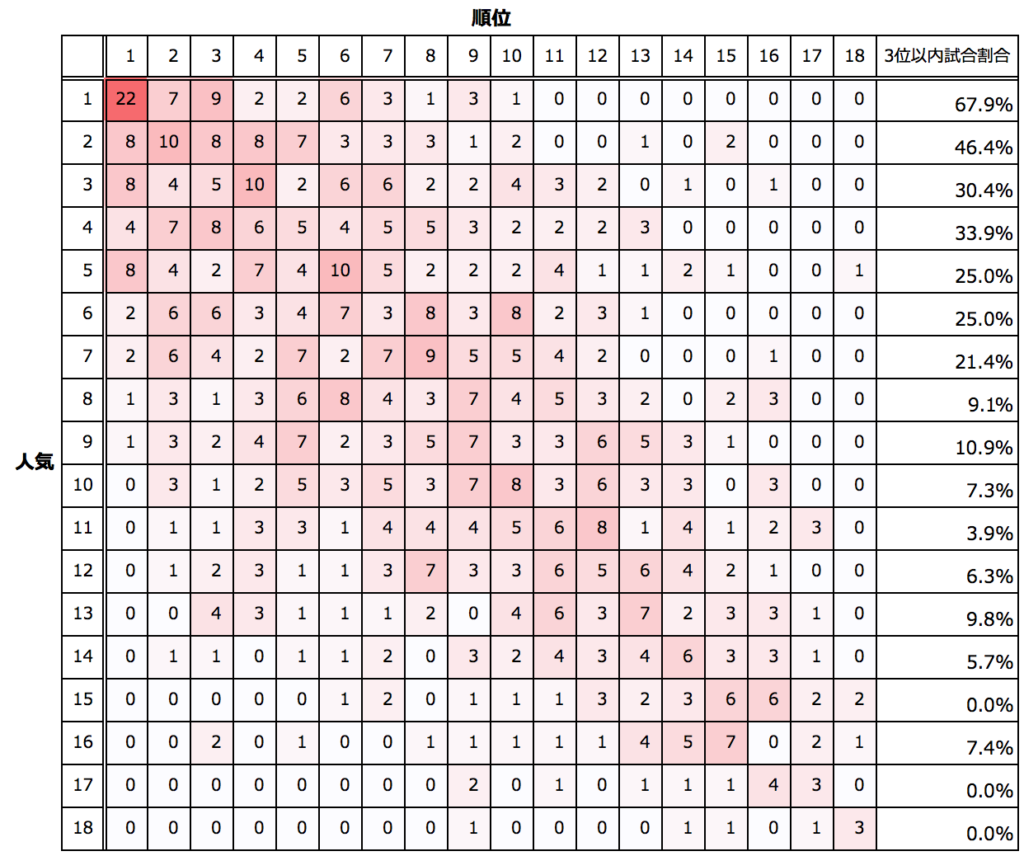
かなりの精度で人気が順位を反映していることがわかります。
1番人気の馬はこれまでの傾向ですと必ず10位以内には入りそうです。
どころか、3位以内に入る可能性が67.9%あります。
2番人気は3位以内に入る可能性が46.4%となります。
ところが、3番人気以降は、7番人気くらいまでやや団子状態となっておりまして、
上位3頭を当てるのは、なかなか難しそうです。
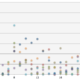
ちなみに、有馬記念における、
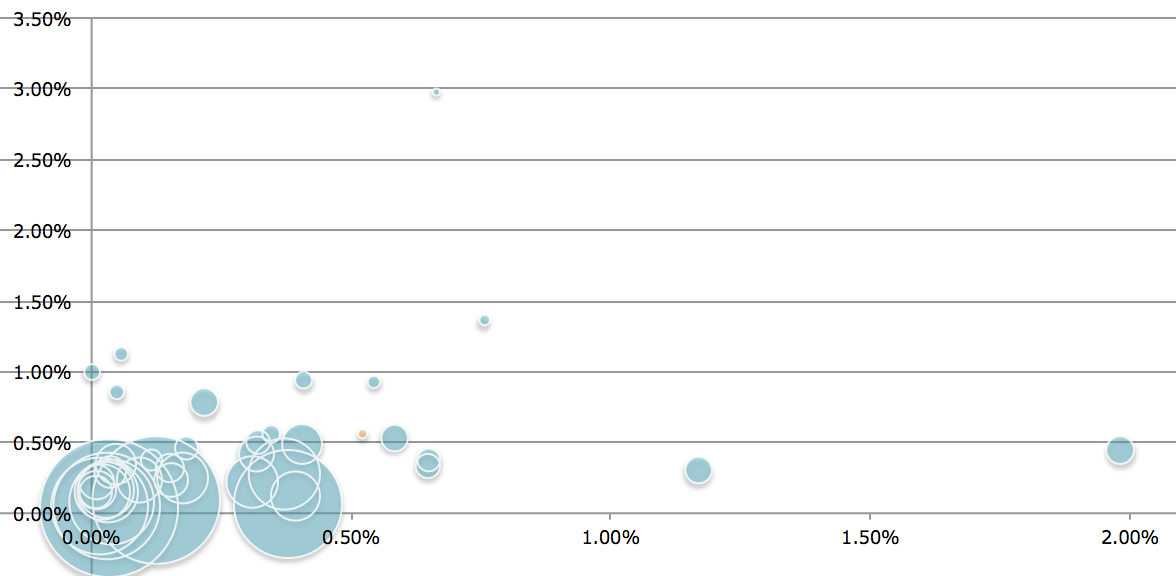
年ごとの人気(オッズ)と実際の順位の相関係数の推移は、下記となります。
※縦軸:人気と順位の相関係数、横軸:年
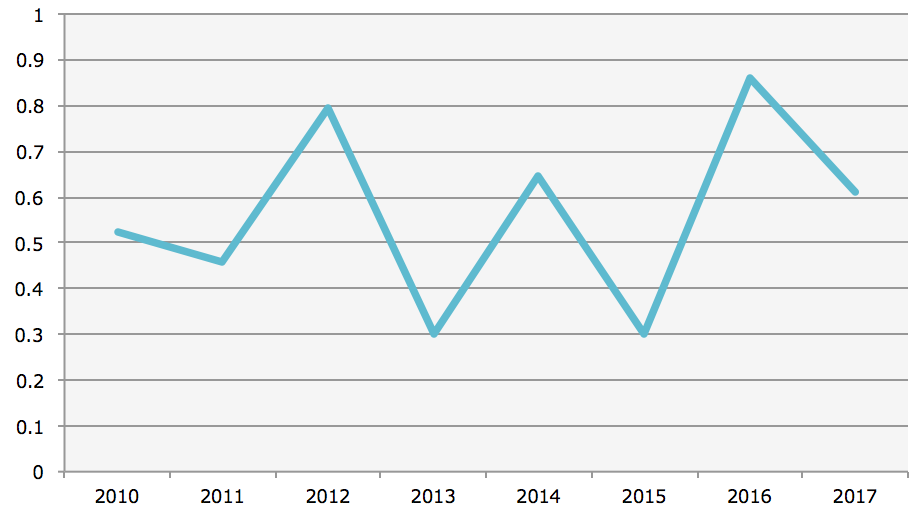
年ごとに、データ分析を行う人が増えているとか、その精度が向上している、という傾向は
この表からはわからず、むしろ、興味深いことに、順当な年と荒れる年が交互に来ているようです。
それに従うと、2018年は順当な年、ということでしょうか。
これは、偶然かと思いますので、いったん気にしないことにします。
ここまでのことから、人気は最終的なモデルの妥当性チェックのほか、
3位以内を予測するときの足切りに使えそうです。
次に、今回収集したレースデータのうち、2500mレースのみに絞った上で、
ゴールtimeの頻度を集計してみます。
※縦軸:頻度、横軸:2500mレースにおけるtime(秒)
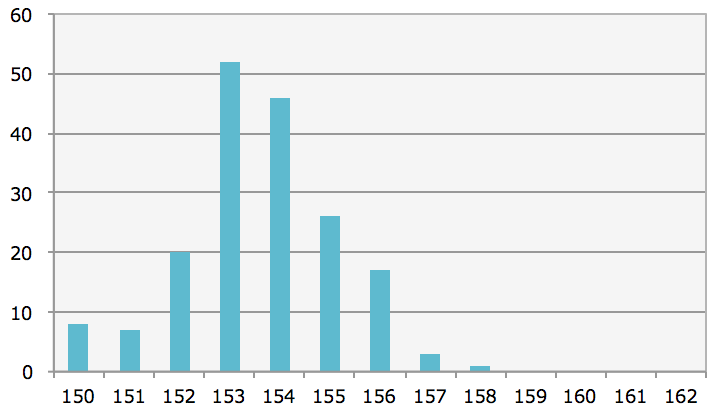
153秒台が最頻値、154秒台が次いでおります。
153秒台の壁を突破したことがある馬は相当早いですね。
逆に、155秒台を突破できない馬は厳しいかもしれません。
しかし、各レースとも、1秒以下の0コンマ秒の戦いが多いようです。
これ、もう1回やったら順位変わるのでは、と素人としては思ってしまうレースが多かったのですが、
とはいっても、業界の方々からすると、0コンマ秒の違い、は明確に実力差として違うものなのかもしれません。
取り急ぎ、先程のデータセットに「馬ごとのベストタイム(正確にはベストペース)」を加えることにしました。
それから、レースごとのコースの距離によって、平均走破ペースがどのように違うのかも見ておきましょう。
下記は、横軸がコースの距離、縦軸がその距離における平均ペース(m/秒)となります。
※縦軸の範囲は0始まりではなく、15.4(m/秒)〜17.0(m/秒)であることに留意
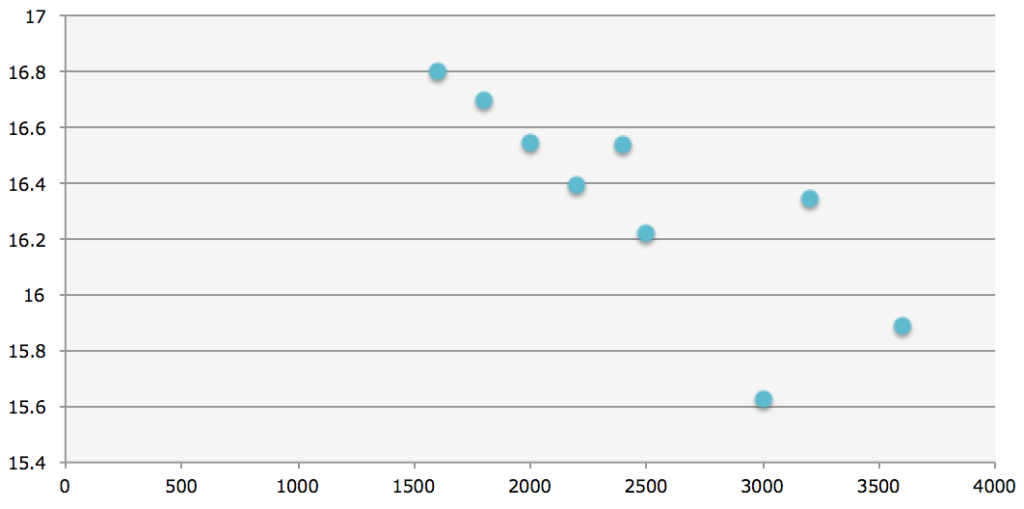
上記を見ますと、コースの距離が長くなるほど、平均ペースは下がるように見え、実感にあっております。
まだまだ探索してみたいところですが、時間が限られております為、
機械学習していきます。
データセットから2017年有馬記念、のデータを抜いてvalid dataとし、
残りのデータをtrain dataとtest dataに分けて学習、モデルを作成し、
valid dataの順位を予測することとします。
また、今回は、”time”を予測することで、その”time”の早いものから順位を計算する、
という方法をとることにします。
※正直、最後まで、順位を予測するか、timeを予測するか悩んだのですが。。
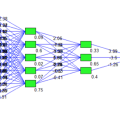
まずはXGBoostを用いて、レースごとの各馬の”time”を予測するモデルを作成してみます。
パラメータチューニングを行った結果、予測結果と実際のtimeの
RMSEは、1.36887となりました。
その時の、”time”の予測に必要な重要度は、下記となりました。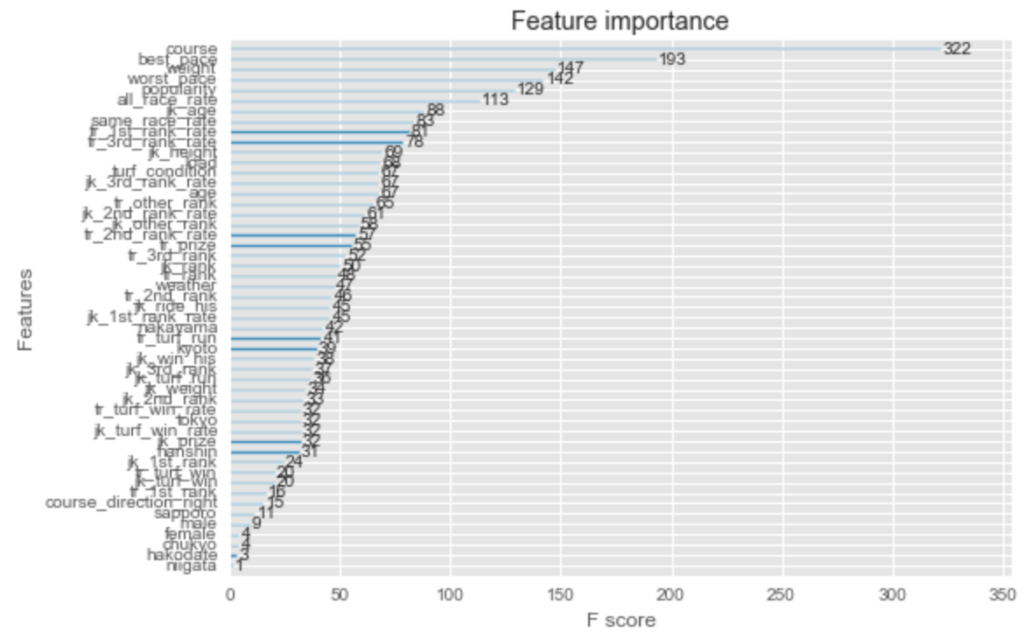
「コースの長さ」「その馬のベストペース」「その馬の体重」「その馬のワーストペース」「人気」「その馬のすべてのレースの平均ペース」、が、
“time”の予測に重要視しているようです。
さて、このモデルで予想した”time”で順位予想をするとどうなるのでしょうか。
XGBoostのモデルを、今回、学習に用いていない有馬記念2017に当てはめて、予測をしてみます。
| 馬 | 予測タイム(秒) | 実際のタイム(秒) | 人気 | 予測順位 | 実際の順位 |
| キタサンブラック | 152.27728271 | 153.6 | 1 | 2 | 1 |
| クイーンズリング | 152.74690247 | 153.8 | 8 | 4 | 2 |
| シュヴァルグラン | 152.56903076 | 153.8 | 3 | 3 | 3 |
| スワーヴリチャード | 150.85598755 | 153.8 | 2 | 1 | 4 |
| ルージュバック | 153.4576416 | 154 | 10 | 11 | 5 |
| シャケトラ | 154.23501587 | 154.1 | 7 | 15 | 6 |
| サウンズオブアース | 152.75093079 | 154.2 | 14 | 5 | 7 |
| レインボーライン | 153.73939514 | 154.3 | 9 | 13 | 8 |
| サトノクロニクル | 154.55477905 | 154.3 | 11 | 16 | 9 |
| ヤマカツエース | 153.33999634 | 154.4 | 6 | 10 | 10 |
| ミッキークイーン | 153.06874084 | 154.5 | 5 | 8 | 11 |
| ブレスジャーニー | 153.9833374 | 154.6 | 12 | 14 | 12 |
| サトノクラウン | 152.78599548 | 154.6 | 4 | 6 | 13 |
| トーセンビクトリー | 153.03562927 | 154.8 | 15 | 7 | 14 |
| カレンミロティック | 153.22950745 | 155.1 | 16 | 9 | 15 |
| マルチサクラアンプルール | 153.65354919 | 155.5 | 13 | 12 | 16 |
上位に注目しますと、人気では8位だった、クイーンズリングを4位と予測できているあたり、よいですね。
1〜4位について順位は異なるものの、4位以内の馬は当てることができております。
3連単(1〜3位までの馬を順位も含めて当てる)は厳しくても、3連複(1〜3位の馬の組み合わせを当てる※順位不問)狙いなら、
あるいは、、というところでしょうか。
人気が下位(13位以下)だった馬は、実際の順位も下位だったので、そこは、うまく調整したいところです、が、
人気14位だった、サウンズオブアースが7位と、人気に対して健闘しているので難しいところです。
※ただ、競馬の特性上、3位以降をあてる必要はないのですが、。。
ちなみに、下記は、上記表のうち、予測タイム(縦軸)と実際のタイム(横軸)をグラフにしたものとなります。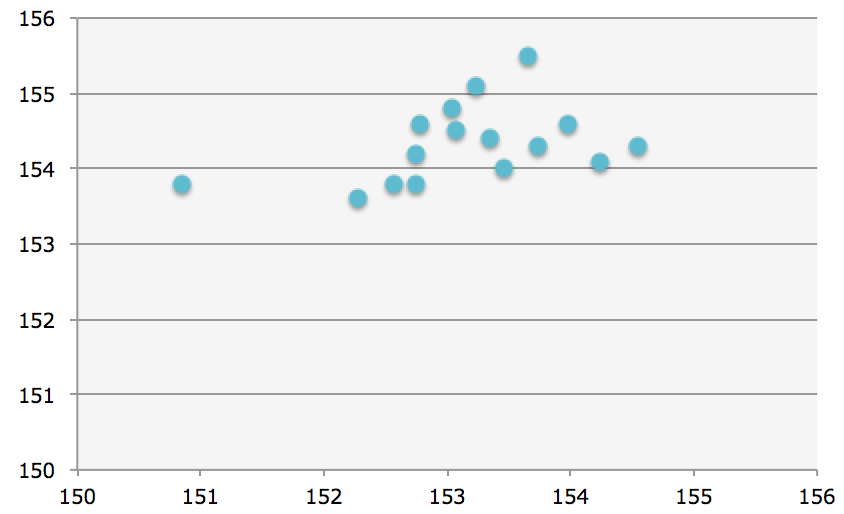
一応、DeepLearningも用いてみたのですが、500回の学習でRMSEは、1.8572となり、
XGBoostの1.36887には及ばず、アンサンブルはやめて、XGBoost単体で挑むことにいたしました。
※下記は、DeepLearningにおける学習ごとのRMSEの変化
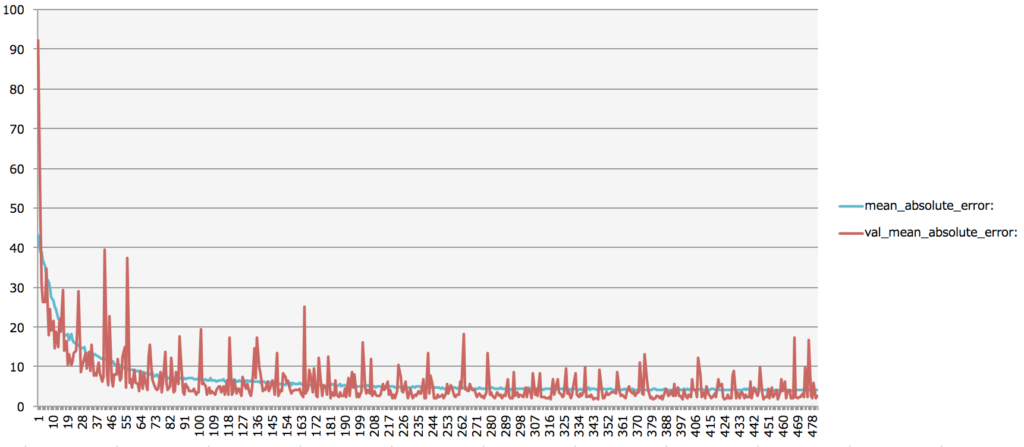
では、いよいよ、このモデルを用いた有馬記念2018を予測してみます。
結果は下記となりました。
| 馬 | 予測タイム(秒) | 人気 | 予測順位 |
| シュヴァルグラン | 151.72097778 | 9 | 1 |
| キセキ | 151.76571655 | 3 | 2 |
| レイデオロ | 152.00489807 | 1 | 3 |
| サトノダイヤモンド | 152.4644165 | 6 | 4 |
| オジュウチョウサン | 152.57821655 | 2 | 5 |
| ミッキースワロー | 152.59020996 | 11 | 6 |
| パフォーマプロミス | 153.14039612 | 7 | 7 |
| ミッキーロケット | 153.20953369 | 8 | 8 |
| スマートレイアー | 153.34529114 | 16 | 9 |
| ブラストワンピース | 153.36836243 | 4 | 10 |
| モズカッチャン | 153.43286133 | 5 | 11 |
| サウンズオブアース | 153.49943542 | 14 | 12 |
| クリンチャー | 154.20393372 | 10 | 13 |
| サクラアンプルール | 154.64308167 | 15 | 14 |
| マカヒキ | 155.06196594 | 12 | 15 |
| マルチリッジマン | 156.50730896 | 13 | 16 |
シュヴァルグラン!!!
人気では9位ですが、去年の有馬記念で3位、今年の天皇賞(春)でも2位となっております。
ちなみに、シュヴァルグランの過去レースを参照しますと、上記タイムは十分狙えると思います。
(長距離が得意な馬ではあるようですが)
といいつつ、私は普段競馬をやらないので、もはや、この結果が、ありよりのありなのか、なしよりのありなのか、
よくわかりません、。
とにかくこの結果を信じて、予測結果上位5位予想までの3連複に、ボーナスをつぎこんできます。
だって、このままじゃ、自分の人生、何も変わらない。
こんなに、データサイエンスの力を信じて、有馬記念前日の深夜3時まで、
モデルをチューニングし続けているんだから。
未来を変えたいんだろ?だったら自分のデータを信じなきゃ!明日、この未来にベットする!!
わあああああああああああ!!!!(続く)
| (5) 当日の有馬記念の様子
※2018/12/24追記。
当日は、中山競馬場で結果を見届けるべく、西船橋までやってきました。
暗雲立ち込める曇り空の下、ちょうどレース開始時間には小雨か、という予報です。
当日の西船橋駅は、すでに駅のホームから混雑しており、
駅構内のスタバですら、競馬新聞を見ているカップルでいっぱいです。
西船橋駅から中山競馬場までは、バスもでているのですが、
せっかくなので30分ほどかかりますが、歩いて向かうことにしました。
道中、同じように歩いて向かう方も多く、気分が盛り上がってきます。

中山競馬場の近くはアコム、レイク、アイフル、が完備。お金がなくてもバッチリですね。

初めて来ました、中山競馬場!
さすがの大混雑ですが、大勝負前の緊張感にみちています。
せっかくなので、競馬新聞を購入。シュヴァルグランはどうなんだ!?
佐藤直文さんも、いいとおっしゃっております!
案外、良い予測なのではないでしょうか。
混雑する前に、馬券を購入しなければ、
と思いましたが、シートに記入するだけでスムーズに買うことができました。

シュヴァルグランが映るたびに、胸が高まる!恋でしょうか。
もつ煮込みとビール。「悪魔的に、うめー!」(※カイジ風)
いよいよ、勝負の時が近づいてきました。
おなじみのレース開始のファンファーレ。会場の一体感がすごい。
データサイエンスの結果を信じて、予測結果上位5位予想までの3連複に、
ボーナスをつぎこんだ馬券を握りしめて、今ここにいる。
だって、このままじゃ、自分の人生、何も変わらない。
こんなに、データサイエンスの力を信じて、有馬記念前日の深夜3時まで、
モデルをチューニングし続けたんだから。
未来を変えたいんだろ?だったら自分のデータを信じなきゃ!いま、この馬券の示す未来にベットする!!
わあああああああああああ!!!!
はずれました。
| (6) 結果
※2018/12/24追記。
JRA公式より2018年第63回有馬記念の結果。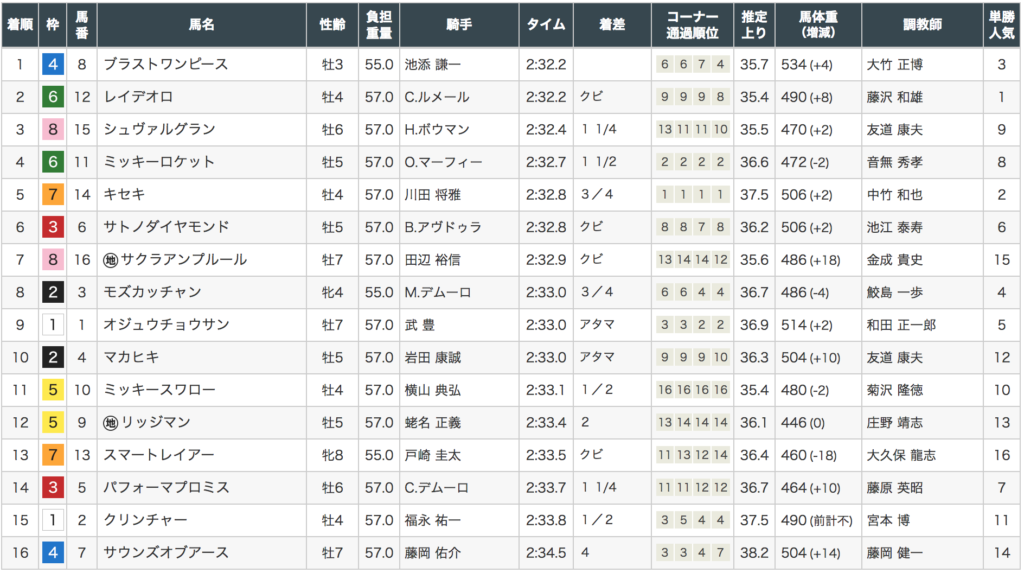
1位と3位のシュヴァルグランは0.2秒差でした。
ブラストワンピース、レイデオロは上位人気、だったことを考えると、
シュヴァルグランの上位を予想できたことは、少し満足感があります。
ブラストワンピースは、前日の4番人気から、さらに当日人気を上げてきたこと、
当日の天気、芝状態は直前まで変動しておりました。
来年はPCを会場に持参して、ぎりぎりまで粘った入力を入れて、予測を出そうと思う次第です。
会場に響き渡る「いっけぞえ!いっけぞえ!」という、池添騎手に対する惜しみないコール。
目に浮かぶ水分は、涙なんかじゃない。西船橋に降り注ぐ小雨です。
ではまた来年。さよならボーナス。ありがとうシュヴァルグラン。
関連記事:

人気記事: