Article
・Kaggleやデータ分析初学者向けのチュートリアル解説本を執筆しました。本記事とあわせてご参照くださいませ。

・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
はじめに
本記事では、2021年2月までKaggleで開催された、“Cassava Leaf Disease Classification”コンペ、
通称、”cassavaコンペ”を振り返ります。
PyTorchで画像処理の勉強をしていたときにタイミングよく開催されたコンペでした。
画像コンペでは初めてソロで参加し、Silverメダルとなりました。
目次
1) コンペの概要 | オーソドックスな画像処理コンペ
2) 本コンペの特徴 | ノイジーなラベルと画像
3) やったこと | 各取り組みとその時点でのスコア
4) 結果 | 103位でSilverメダル
5) 1位解法 | 多様なウェイトとアーキテクチャ
6) 参考情報 | 画像処理Tips集
1) コンペの概要 | オーソドックスな画像処理コンペ
2) 本コンペの特徴 | ノイジーなラベルと画像
3) やったこと | 各取り組みとその時点でのスコア
4) 結果 | 103位でSilverメダル
5) 1位解法 | 多様なウェイトとアーキテクチャ
6) 参考情報 | 画像処理Tips集
| (1) コンペの概要 | オーソドックスな画像処理コンペ
cassavaコンペは、キャッサバの葉の画像から、
その葉の健康状態を4つの病気の症状あるいは健康、の5つに分類するものとなります。

キャッサバは過酷な条件でも栽培できアフリカで2番目に炭水化物を供給する作物であるものの、
ウイルス性疾患が低収量の原因となるため、健康状態の早期の見極めが重要であるということが、
コンペの開催背景となります。
データは、ウガンダでの定期的な調査により収集された21,367枚の画像データセットとなります。
多くの画像はウガンダの農家にクラウドソーシングして撮影され、専門家によってラベル付けされています。
与えられるデータは下記となります。
– train.csv:train_imagesのlabel
– sample_submission.csv:サンプルのsubmissionファイル
– label_num_to_desease_map.json:画像につけられたlabelと健康状態の対応表
– train_images:学習用の21,367枚の画像
– test_images:テスト用の画像(サンプルの1枚のみ)
– train_tfrecords:tfrecord形式の学習画像
– test_tfrecords:tfrecord形式のテスト画像
分類する健康状態は次の5つとなります。
0: ‘Cassava Bacterial Blight (CBB)’

1: ‘Cassava Brown Streak Disease (CBSD)’

2: ‘Cassava Green Mottle (CGM)’

3: ‘Cassava Mosaic Disease (CMD)’

4: ‘Healthy’

本コンペはcodeコンペのため、テスト画像は手元には与えられず、
推論用のモデルを作成しKaggle上で推論コードを実行、
隠されたテスト画像に対して予測することになります。
(推論制限時間9時間)
画像コンペとしては非常にオーソドックスで取り組みやすいかと思います。
一方で、ノイジーなラベルと画像が多いと言う問題もありました。
| (2) 本コンペの特徴 | ノイジーなラベルと画像
・ノイジーなラベルと画像
様々なdiscussionで議論されましたが、
与えられたデータのラベルおよび画像が非常にノイジーでした。
例えば健康な葉にも病気のラベルがつけられていたりその逆もあったり、
[ラベルミス?:’Healty’とラベル付けされている’CMD’のような画像]

[ラベルミス?:’CMD’とラベル付けされている’Healty’のような画像]

学習データ同様にテスト画像もノイジーなのかどうか、もし学習データ同様にノイジーな場合、
正しくモデルの性能を評価できないのではないか、という点が問題視されました。
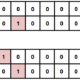
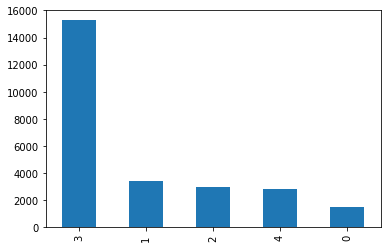
・データが不均衡
これは難しさというより一般的に起こり得る対処できることですが、
5つの健康状態それぞれの画像が均等に用意されているわけではありませんでした。
特にCMD(Cassava Mosaic Desease)の画像が他ラベルと比較して多い状態でした。
[5つのlabelごとの画像数]
その他、考慮すべき点・難しかった点として、
実は葉以外の茎や根の画像もそれなりにあり、人間が写っていたり写真を複写したようなものもありました。
これらをどのように扱うかという問題もありました。
[茎や根の画像]


[写真を複写しているような画像]

また推論制限時間が9時間であることは非常に妥当でありますが、
コンペ終盤では多くの複数モデルで予測させてアンサンブルしようとすると時間内に収まらず苦労しました。
| (3) やったこと | 各取り組みとその時点でのスコア
やったことは画像処理コンペで一般的に行うことを一通り試した、という感じですが、
効果があったこと、なかったことを整理するために備忘録のために、
時系列ごとに各時点でのスコアとともに一通り記しておきます。
・ベースラインの生成(public:0.8531 / private:0.8586)
とりあえずデータローダーから予測まで一通り動くコードを作ろうと思い、
resnextを用いて、train_test_splitしたもので一通り動かしました。
・Data Augmentationの実装(public:0.8643 / private:0.8652)
次にAugmentationをalbumentationパッケージで書き直し、
いくつかのAugmentationを検証、追加しました。
・2019データの追加(public:0.8635 / private:0.8672)
cassavaコンペは過去にも開催されており、
(今回よりもさらにノイジーで画像サイズも小さいものの)過去データを追加することが
有用であるdiscussionをみつけ、自分の環境でも試しました。
・stratified-k-foldで3分割(public:0.8664 / private:0.8679)
ここまで単純にtrain_test_splitしたもので試していましたが、
ここでlabelごとにstratified-k-foldで3分割したコードに修正しました。
もう少し早い時点でfold分けをしておいたほうが良かったかもしれません。
・様々なアーキテクチャでアンサンブル(public:0.8705 / private:0.8720)
ここまでのコードをもとに様々なアーキテクチャに変更して実装、アンサンブルしました。
試したのは、もともとのresnextのほかに、
efficientnet-b3、efficientnet-b4、efficientnet-b7、se-resnext、
を検証しました。
・TTA追加(public:0.8733 / private:0.8772)
ここまで実装したコードで、推論時にTTA(Test Time Augmentation)を追加しました。
とりあえずこの時点では学習時と同じAugmentationを5回かけていました。
・loss、optimizer、schedulerを変更(public:0.8773 / private:0.8831)
noisyなデータに対して、bi_tempered_logistic_lossが良いというdiscussionを見つけ、
それを実装するとともに、このタイミングでoptimizer、schedulerもチューニングしました。
・high error画像を学習から除去(public:0.8824 / private:0.8876)
今回noisyなデータであることから、学習したモデルで予測を大きく外す画像がありました。
それらのerror上位1000枚ほどの画像を学習から除去して再度学習し直しました。
・mix upを追加しskfを10foldに(public:0.8844 / private:0.8844)
mix upがnoisyなデータに対して有用であるというdiscussionを見つけ、
(1つのlabelにhardにlabelingするのではなく、各labelに確率的にsoftにlabelingするため)
この段階でAugmentationにmix upを追加しました。
またskfを10foldまで増やしました。
・画像サイズ変更(public:0.8955 / private:0.9005)
ここまで実験効率を優先し、小さい画像サイズで試していましたが、
このタイミングで各アーキテクチャとも448×448、512×512まで大きくしました。
画像サイズはもう少し早いタイミングで大きくしても良かったかもしれません。
・TTAを5回から10回に増やす(public:0.8977 / private:0.9016)
ここまでTTAは5回でしたが、もう少し増やしてもよいのではと思い、
10回に増やしました。またTTA時にoriginalな画像を残したほうがよいという過去コンペのTipsを見つけ、
TTA時の最初の1回はAugmentation無しとしました。
・(没)茎や根などの画像を分けて学習(public:0.8919 / private:0.8928)
ここまで葉や根や茎などの画像を一括で学習していましたが、
それぞれ特徴が異なるため分けたほうがよいのではと思い、別々に学習させました。
ただ葉以外の画像は100枚ほどと少なく、精度が悪化したため没にしました。
・(没)StyleGANで画像を増やして学習(public:0.8966 / private:0.8987)
学習画像が少ない症状の画像を増強するため、
Healthyな画像に対して、StyleGANでその症状の画像を500枚ほど作成して、学習画像に加えました。
生成された画像は悪くない気がしたのですが、精度が悪化したため没にしました。
・学習時に最後はAugmentationを緩める(public:0.8964 / private:0.9027)
ここらへんの段階でfmixをepoch序盤では追加しました。
また学習時のAugmentationはepochの終盤では緩めたほうがよいという過去コンペのTipsをみつけ、
cutmix、fmixや輝度コントラスト調整などのいくつかのAugmentationをepochの最後の5回では外して学習しました。
・アンサンブル調整(public:0.8995 / private:0.9079)
最後にここまで作成したアーキテクチャにさらにVision Transformerなどを加えて、
アンサンブルのウェイトを調整しました。
noisyなデータが多い”おみくじコンペ”と揶揄されていた本コンペではありますが、
振り返ってみると、cvとpublic、publicとprivateの相関はそれなりに取れていたように思います。
画像処理のキャッチアップもかねて参加したコンペではありますが、
理想を言えば上記をコンペ中盤までに終わらせて、
終盤はもう一歩踏み込む余地があれば、というところではありました。
| (4) 結果 | 103位でSilverメダル
最終的に3900チーム中、public:20位、private:103位で、
Silverメダル(上位5%以内)となりました。
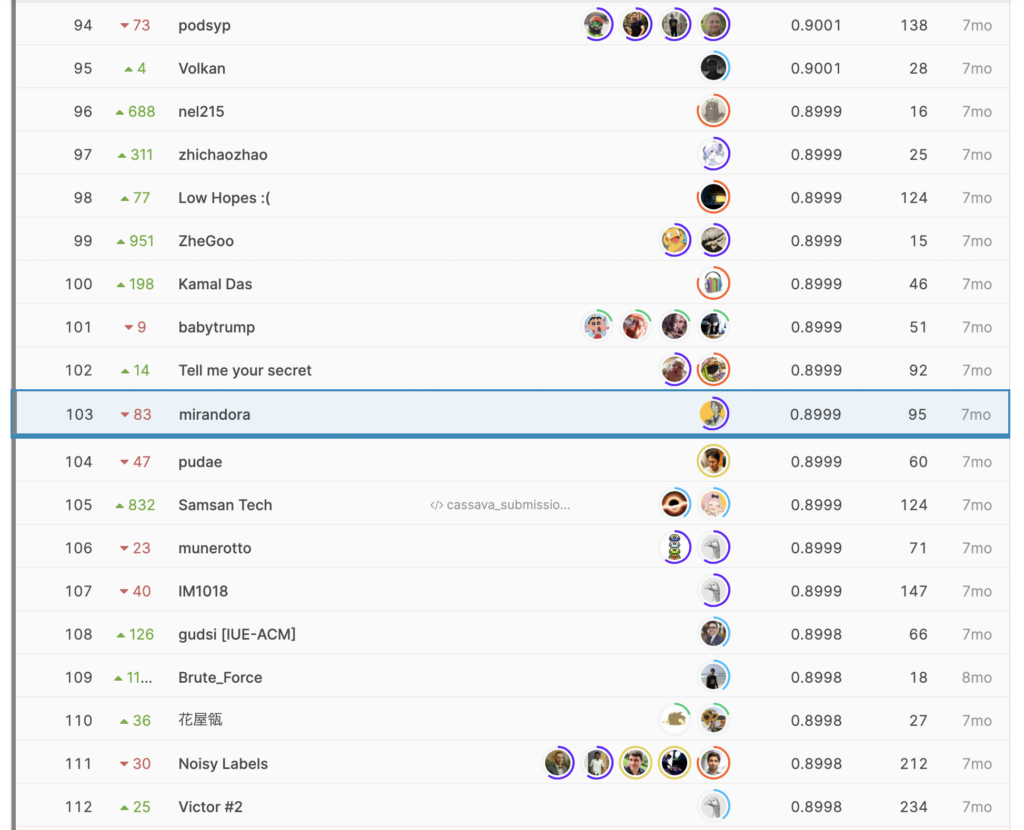
コンペ期間中、コンスタントに精度を改善することができ、
publicであと2つ順位を上げることができればGoldメダルという、
スコアに食い込めました(かつ、publicのスコア表示上はGold圏と同じスコア)。
手持ちのサブでもっとprivateのスコアが良いものを選択できず、
shake downになったのは残念ですが、
初めてソロで完走した画像コンペで、
画像処理でやるべきことの学習としては非常によい体験でした。
テーブルコンペではbaselineコードがある程度整理できていますが、
画像処理についても一通りコードが整理できたのもよい機会でした。
| (5) 1位解法 | 多様なウェイトとアーキテクチャ
本コンペは、shakyかつスコアが詰まっていた中で、
1位チームは2位チームにスコア差をあけた上で、public/privateともに1位でした。
下記が、「1st Place Solution」で紹介された1位解法となります。
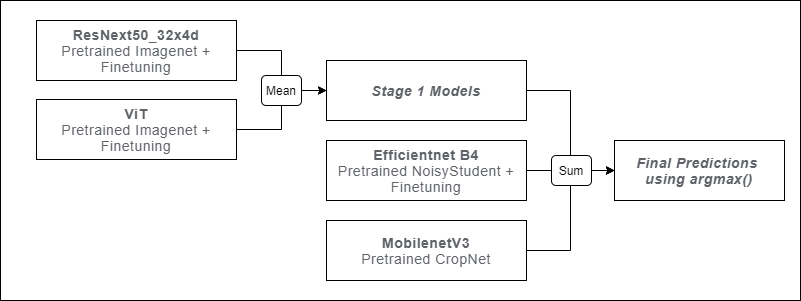
ポイントは下記となります。
・ひとつの高精度に調整したモデルよりもアンサンブル用に大量のモデルを試した。
さまざまな事前学習済みのウェイト(Imagenet、NoisyStudent、Plantvillageなど)で、
さまざまなアーキテクチャを試した(すべてのEfficientNetアーキテクチャ、Resnet、ResNext、Xception、ViT、DeiT、Inception、MobileNetなど)
・勝利の鍵はTensorflow HubのCropNetを使用したこと。単体では性能よくなかったが、アンサンブルで効果的だった。
・モデルごとに、loss、スケジューラー、epochを変える。
解法を読んだときによくあることですが、
言われてみるとなぜ自分もこうしなかったんだろう、これを試さなかったんだろうと思い悔しいですが、
画像処理において本質的な実験をスピーディーに実行するための準備が自分にはまだ足りていなかったと思いました。
今回のコンペのコードを整理して、次回からはより効率的に様々なことを試せるようにしておこうと思いました。
| (6) 参考情報 | 画像処理Tips集
最後に、画像コンペに参加するに当たり、非常に参考になった/なる情報をまとめておきます。
・『PyTorchによる発展ディープラーニング』
PyTorchで画像処理をはじめるための入門書です。
画像分類、物体検出、セマンティックセグメンテーション、姿勢推定、GAN、異常検知、など
豊富な画像処理タスクをPyTorchのコードを実装しながら学ぶことができます。
・「【Kaggle】2020年に開催された画像分類コンペの1位の解法を紹介します」
2020年にKaggleで開催された画像コンペの概要と1位解法を紹介している記事です。
画像コンペでご活躍されているKaggle Masterの方がまとめられているだけあって、
各コンペの特徴や難しさ、1位解法について重要なポイントを抑えた上で端的に記載されており、
非常に有用かつわかりやすいです。
・「Practical tips for handling noisy data and annotaiton」
KaggleDays Tokyo 2019で発表されたSlideです。
Noisyなdataやannotationに対してどのような処理をすればよいかというTips集で、
まさに本コンペでも有用な情報でした。
・「backbone としての timm 入門」
こちらはcassavaコンペで参照した資料ではなく、コンペ半年後に開催された第3回分析LT会にて発表された資料です。
今回のコンペでもtimmを様々なアーキテクチャの事前学習済ウェイトで用いていますが、
最新のモデルもどんどん追加されているようですので、
今回使用したモデル以外も引き続きキャッチアップしていきたいです。
・「Tensorflow/Pytorch モデル移植のススメ」

こちらも先程のものと同様、第3回分析LT会にて発表された資料です。
私は画像処理のコードはPyTorchで実装することが多いですが、
今回のコンペのように多様な学習済みウェイト、アーキテクチャを試すために、
モデル移植の方法は習得しておきたいと思いました。
以上、cassavaコンペの振り返り記事でした。
最後に。この記事はコンペ終了後7か月後に書いているのですが、
当時のことを思い出すのに非常に苦労しました。
振り返りはすぐに書くということと、あとから簡単に取り組みを振り替えれるよう、
リアルタイムにNotionなどでまとめておく、ということの大切さを痛感いたしました。
関連記事:




人気記事: