Article

・Kaggleやデータ分析初学者向けのチュートリアル解説本を執筆しました。本記事とあわせてご参照くださいませ。
『Pythonで動かして学ぶ!Kaggleデータ分析入門』

・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
はじめに
今回はKaggle睡眠コンペこと、「Child Mind Institute – Detect Sleep States」の参戦振り返り記事となります。
去年はコンスタントにkaggleに参加しておりましたが全てbronzeと成績は振るわず、少しだけ充電期間を経て本格的に参加したコンペとなります。
これまで途中参加が多かったのですが、初めて開始日から3ヶ月参加したコンペとなります。(途中、海外旅行や仕事の都合で中断はありつつ)
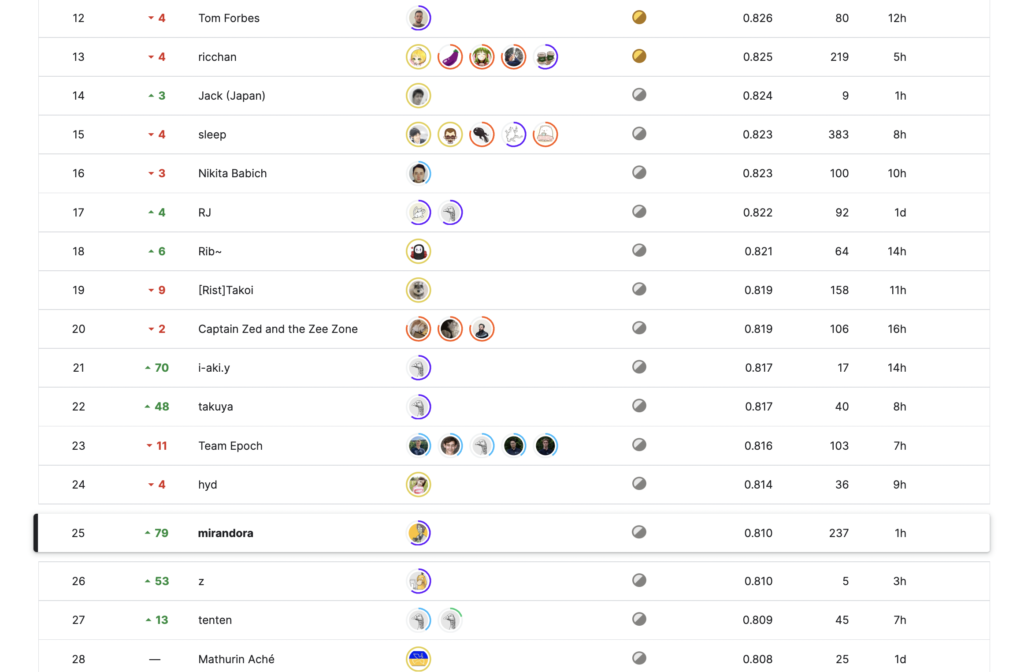
結果はprivate LB25位となりました。本記事では本コンペの取り組みやscore推移、上位ソリューションを振り返っていきます。
※ちなみにサムネイル画像は、midjourneyにて作成。
| (1) 睡眠コンペの概要
睡眠コンペこと、「Child Mind Institute – Detect Sleep States」とは、
被験者(子どもたち)の手首につけたスマートウォッチの加速度センサの値から、「入眠(onset)」と「覚醒(wakeup)」を予測するものです。
データは、下記が与えられました。
・train_series.parquet:277series_idのデータ
| series_id | 被験者ID |
| step | 被験者ごとの時刻step |
| timestamp | 時刻 |
| anglez | z方向加速度 |
| enmo | 全方向加速度のユークリッドノルム |
・train_event.csv
| series_id | 被験者ID |
| night | 各被験者ごとの夜no |
| event | 入眠、覚醒(このeventのstepを予測) |
| step | 被験者ごとの時刻step |
| timestamp | 時刻 |
本コンペはcodeコンペであり、推論はKaggle Notebook上で行う必要がありました。testデータは隠されていたもののtrainデータともに数GBあり、メモリ効率の良い処理の実装が必要でした。(私は序盤、中盤でOOMを連発しsubmitを溶かしていました…。)

評価指標はEvent Detection Average Precisionであり、各イベント(「入眠」「覚醒」)が起きたタイミングを正しく予測できたかを段階的な許容範囲でスコア付けされるものでした。
下記がanglezとenmo、睡眠期間の例となります。


睡眠・起床期間はある程度特定できそうな雰囲気を感じると思いますが、このコンペの私の考える難しさは主に3つあり、どのように対応するか悩みました。
・おおよその睡眠と起床中の期間は分類できそうな中で、「入眠」「覚醒」の正確なタイミングを前処理・後処理含めてどのようなプロセスで求めるか。
・ラベルがノイジーである中で、正解stepとの段階的な許容範囲誤差によるスコア付与がされる評価指標とどのように向き合うか。
・計測がうまく行えていないノイズ期間があり、その期間はeventが付与されない。この期間をどのように特定し扱うか。
| (2) 本コンペの取り組み・解法
本コンペにおける私のアプローチは下記となります。
Data
・データを3種類作成(ローデータ、clean data、clean & relabel data)
- raw dataはそのまま
- clean dataは冗長なノイズ期間を削除
- relabel dataはノイズ除去にさらに手元のモデルでpseudo labelしてあまりにも予測とラベルが異なるものはラベル付けをし直し。
この3種類で学習したモデルをアンサンブル
Model
・モデルはGRU、lossはBCEWithLogitsLoss(dice lossのほうがよかったかも。最後cvでは上回ったが時間切れ)
・23feats(主に序盤に実装したLightGBMにて重要度が高い特徴量)
- 加速度を微分(ちなみに加速度を微分したものは”躍度”というらしい)した特徴量およびそのrolling mean
※特定の値であることではなく加速度が同じ値が続くということに注目(diffでもいいかも)
- (1DCNNやtransformerを使っていないため)中長期のshift/mean特徴量
・シンプルなdown sampling(3stepごと)
PostProcessing
- 冗長なノイズ期間をpredから削除(anglez/enmoの同じ値の繰り返しとなっている区間を特定して除去)
- Butter filterで予測をスムージング
- find_peaks
モデルは正直他の人よりシンプルで差がついていないと思います。ただし特徴量で工夫しました。
特に、1dCNNやtransformerでの精度向上に苦労したため、中長期的な時系列の特徴をNNに分からせるために、
アーキテクチャで工夫するのではなく、特徴量で学習できるようにしました。
その他、特徴的なアプローチとしては、Dataを3種類作成したこととPostProcessingです。
他の方々の多くはData Loaderを工夫してbatchの中のdata chunkごとの多様性を出していたと思われますが、
私の場合はその処理ではあまりCVが良くならず、データ自体をいくつか作成することにしました。
ちなみに、もっともpublic LBが良いのは元のデータで学習したモデルでしたが、その他2つのデータで学習したものは、
アンサンブルには効果的でした。
また、PostProcessingはおそらく本コンペで最重要なパートかつ人によって取り組み方が異なる工夫のしがいがあるパートと思います。
この後処理はコンペ期間中、モデル自体の精度がある程度更新される度に、予測結果を眺めて何度も作り直しました。
一方で上位ソリューションを復習して一番差を感じたのもこのパートになります。
| (3) score推移・結果
本コンペはCVとpublicLB、publicとprivateがある程度相関しており、他コンペと比較して非常に取り組みやすかったです。
※下記横軸:public_score、縦軸:private_score
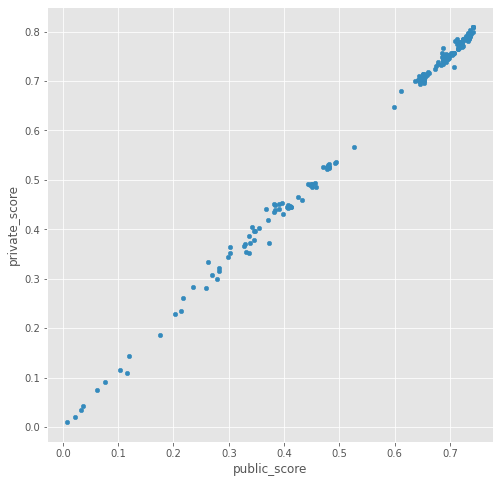
しかし、特に終盤はsilver前後はスコアが僅差で密集していたため、publicの順位自体には執着しすぎないように気をつけました。
あくまで自分の中で、CVの目標スコアを目指すように実験管理していきました。
※これまで幾度となく、public順位に執着しすぎて(overfitして)shake downしたため…。
ここではコンペ中の主だった取り組みとそれに伴うスコア推移を記録しておきます。
・lightGBMのbaseline (public:0.302, private:0.353)
– 一通りのEDAを経て、いくつかのrolling mean特徴量で学習したもの
– 序盤はlightGBMとNNのアプローチを試していましたが、NNが精度が伸びず試行錯誤していました。
・lightGBMに中長期的なrolling meanやdiff特徴、後処理を追加 (public:0.482, private:0.526)
– このスコアが私の中ではlightGBMでの限界でした。
– この時点までで作成した特徴量がのちのちNNにも活用しているため初手lightGBMの意味はEDA的にもありました。
– この時点の後処理は最終的には使用しなかったものの、評価指標を理解する意味では役立ちました。
– NNも0.4弱くらいにはスコアが伸びたものの、まだ十分な精度ではない状態でした。
・GRUベースのアプローチに変更 (public:0.653, private:0.71)
– ここで公開notebookを参考にGRUベースのアプローチを実装し独自の取り組みを加え、大幅にスコアを伸ばすことができました。
– この時点ではonset/wakeup/otherの3クラス分類、lossはCElossにしていました。
– すでに実装済だったppやlightGBMで使用していた特徴量を一部加えていました。
・アーキテクチャを変更 (public:0.694, private:0.746)
– lossはbi-tempered loglossなど試しましたが精度向上には繋がりませんでした。
– 1dCNNの追加、transformer層の追加など試しましたが精度向上には繋がりませんでした。
– この時点でclean data&relabe dataを作成し、アンサンブルに加え始めました。
– この時点でmodelの更新はval lossではなくvalのscore(評価指標)で行う変更をしました。
・down samplingを変更、特徴量を大幅刷新 (public:0.708, private:0.756)
– down samplingを3step平均をとるのではなく、シンプルに3stepごとにsamplingする方式に変更しました。
– 特徴量をあらためて見直し、lightGBMの上位重要度特徴量、GRUでは考慮しづらい中長期のrolling meanを中心に入れ替えました。
・各ラベルをクラス分類から2値分類に変更 (public:0.722, private:0.770)
– onset/wakeup/otherの3ラベルごとの2値分類に変更し、lossをBCEWithLogitsLossに変更しました。
– 各ラベルの値をgaussian filterをかけたものを予測しました。パラメータはCVで調整しました。
– ようやく1dCNN/UNET/transformerなど各種アーキテクチャが悪くない精度が出るようになってきました。(が、シンプルなGRUの予測がbest)
– lossはfocal lossなど様々試しましたが精度向上には繋がりませんでした。
・submit作成のpost processをさらに変更してアンサンブル (public:0.742, private:0.810)
– predでanglezが一定期間同一の値を繰り返している箇所はpredから除外するpost processを実装しました。
– raw data/clean data/clean data &relabelの3つのデータで学習したものをアンサンブルしました。
NNのアーキテクチャの変更(1dCNNやtransformer層の追加など)に手こずりましたが、
期間中、様々な試行錯誤を通してコンスタントにスコアを伸ばすことができ、楽しいコンペでした。
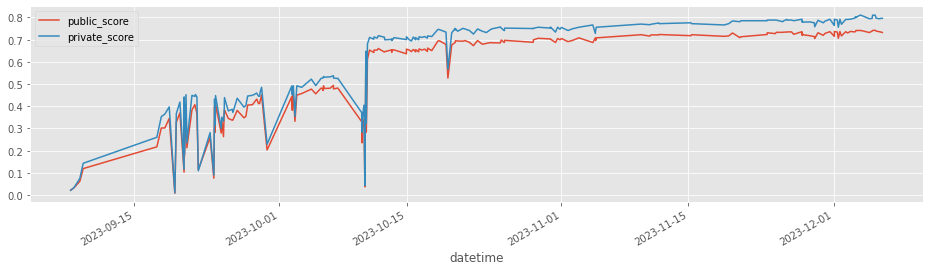
※下記は期間中のpublic scoreとprivate scoreの推移。
※余談ですが、時々奇妙なスコアになっているのはLBProbingのため。
「train/testで重複したseries_idがないか」「testデータが特定期間(シーズン)に偏っていないか」を念のためチェックしていました。
※そんなことは無かったため精度向上には繋がっていませんが、自分の中でありえる可能性を消すためには必要でした。
これまで何度も痛い目を見てきたので…。
| (4) 上位ソリューション
公開されている上位陣のソリューションをみた限り、下記が主要な取り組みだったようです。
・modelは主に1d-CNNあるいはUNET(3位チームはLGBMもアンサンブルに使用)
・dataはseries_idごとにdailyで分割。ただし若干のoffset(余裕幅)をもたせる。
・(繰り返しパターンの)異常値期間をmask。※特徴量に使うチームと予測値のmaskに使うチームあり
・anglez、enmo関連の特徴量(logをとる、日にちごとの統計量をとるetc)
・targetはonset/wakeupを直接予測するチームと、awake/sleepを予測してからonset/wakeupにするチームあり。
・targetを0/1ではなく、ガウス分布などで前後に減衰させた値にして推定。
・post processingはチームごとに異なるが、predのsmoothingからのfind_peaksが多い。更に15分ごとの偏り補正など。
上記に加え今回のようなデータ量を効率的に処理するためにcython、polars、その他デコレータやクロージャなどの実装上の工夫も見られました。
上位陣のコードを実行してみると、modelのためのデータ作成およびmodel学習ともに私の実験コードと比較して驚くほど速かったです。
| (5) おわりに
残念ながら目指していたgoldには届かず、gold圏とはまだまだ差を感じました。
しかし時系列でNNを本格的に取り組んだことや、UNET、1dCNNなどの理解・経験が深まったことは収穫でした。
またこれまでMLBコンペでの26位がprivate最高順位だったのですが、1つ更新して25位で終えることができたことは進捗として悪くないかもしれません。
あとは、気持ち的な問題になりますがこれまで最終日はやや手持ち無沙汰になることが多かったのですが、
勉強会などで他の参加者の取り組み方をお聞きすると、みなさん本当に最後の最後まで粘っていることを知り大変刺激になりました。
そのため本コンペではこれまでで一番最後の最後の瞬間まで自分なりに粘りました。(粘りすぎて最後のsubは間に合いませんでした)
結果的に最後の5サブの中にbest subがありました。
※下記はコンペ終了時点のsubmit一覧。

以上、睡眠コンペの振り返り記事となります。
関連記事:






人気記事: