Article
※本記事はPython・seleniumを用いた、
ログインサイトをスクレイピングする方法の解説となります。
selenium部分はこちらからお読みくださいませ。
| 自分の映画鑑賞は良いものだったのだろうか
みなさま、今年は何本の映画を観ましたでしょうか。
今年は「天気の子」のほか、
「アラジン」「ライオンキング」、「トイストーリー4」「アナ雪2」、
「ターミネーター」「スターウォーズ」などの
大作が多く、当たり年、と言われております。
しかし、実際の興行収入や評価はどうだったのでしょうか。
自分は「観るべき映画」を逃さず観ていたでしょうか。
それとも「残念な映画」を多く観ていてしまったのでしょうか。
近年、多くの映画館では予約サービス、ポイントサービスを実装しており、
様々な会員向けの特典を提供しております。
たとえば109シネマズでは、6回鑑賞で1回無料の特典を
受けることができます。
ちなみに私は109シネマズの会員です。(今の家からの利便性で)
そこで今回は109シネマズの会員ページから映画鑑賞履歴を取得して、
様々な考察をしていきます。
※なお、私はTOHOシネマズの会員ではないですが、
おそらくTOHOシネマズでも同様に履歴取得ができると思います。
| 109シネマズの映画鑑賞履歴データを探る
まずは109シネマズのページを開きます。
※以下、2019年11月時点のレイアウトとなります。
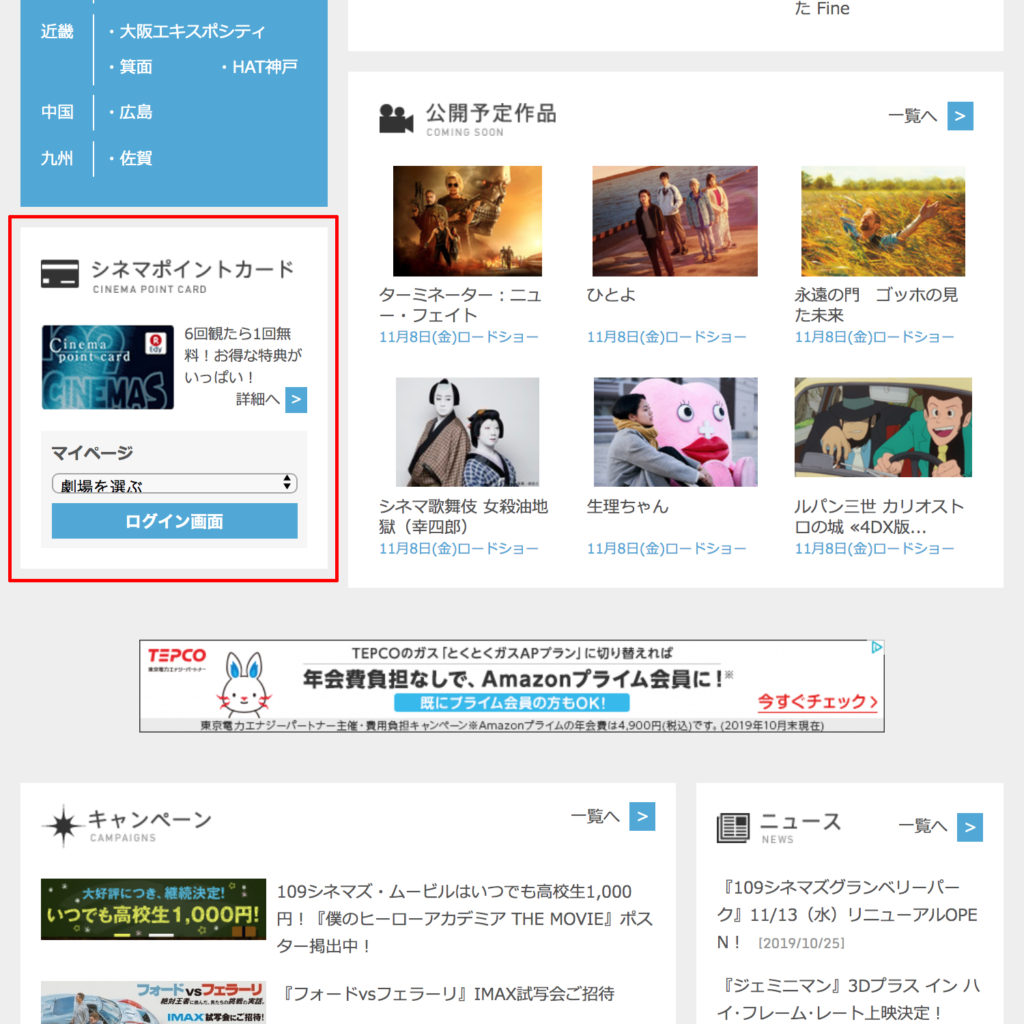
ぺージをスクロールし、中ほどにある”シネマポイントカード”で
劇場を選択し、「ログイン画面」をクリックします。
※ちなみにログイン画面への遷移において、
劇場は全国どこの映画館を選択しても問題ありません。
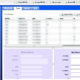
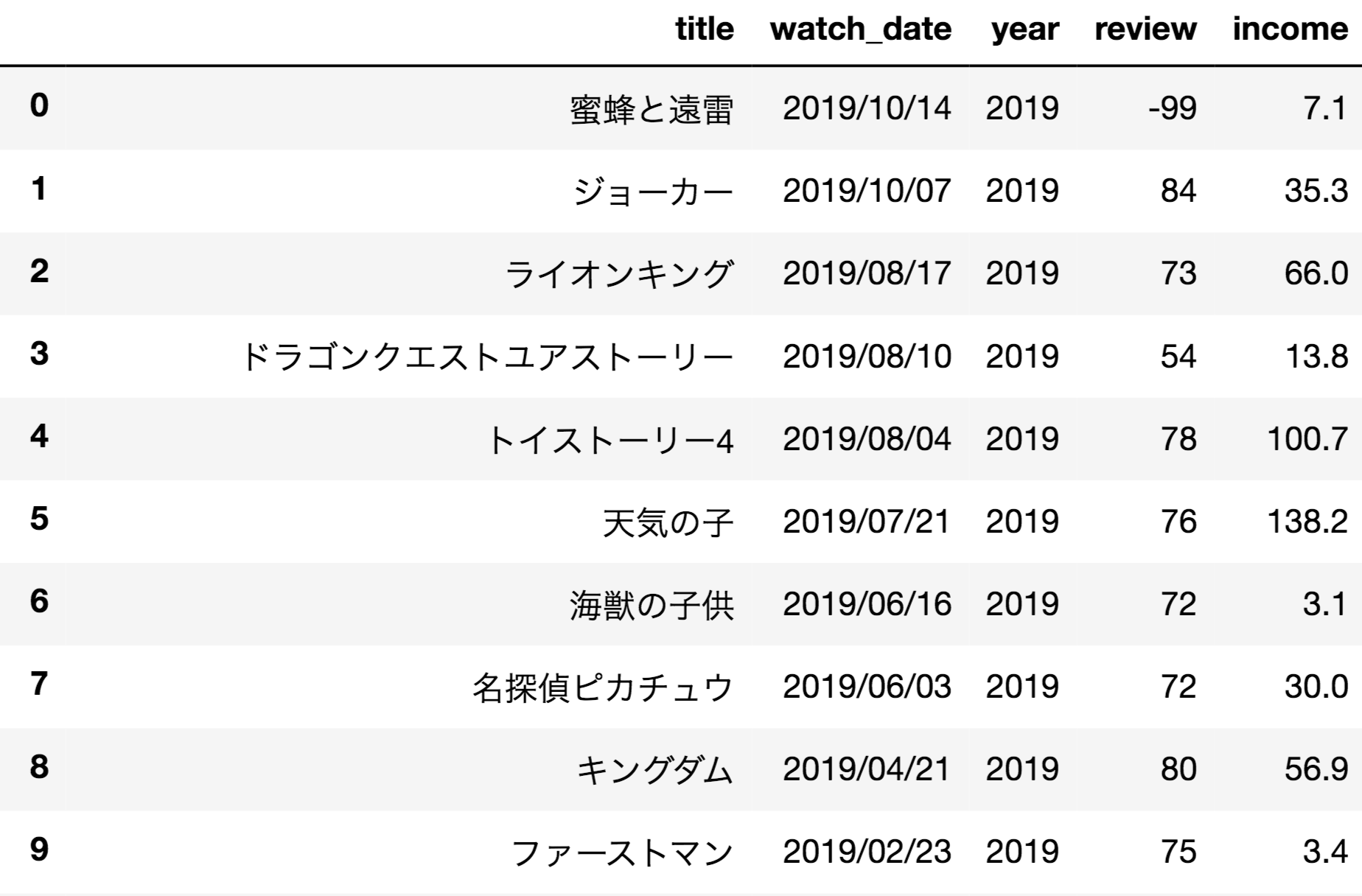
ログインできると、これまで109シネマズで予約した映画の履歴を
一覧でみれます。
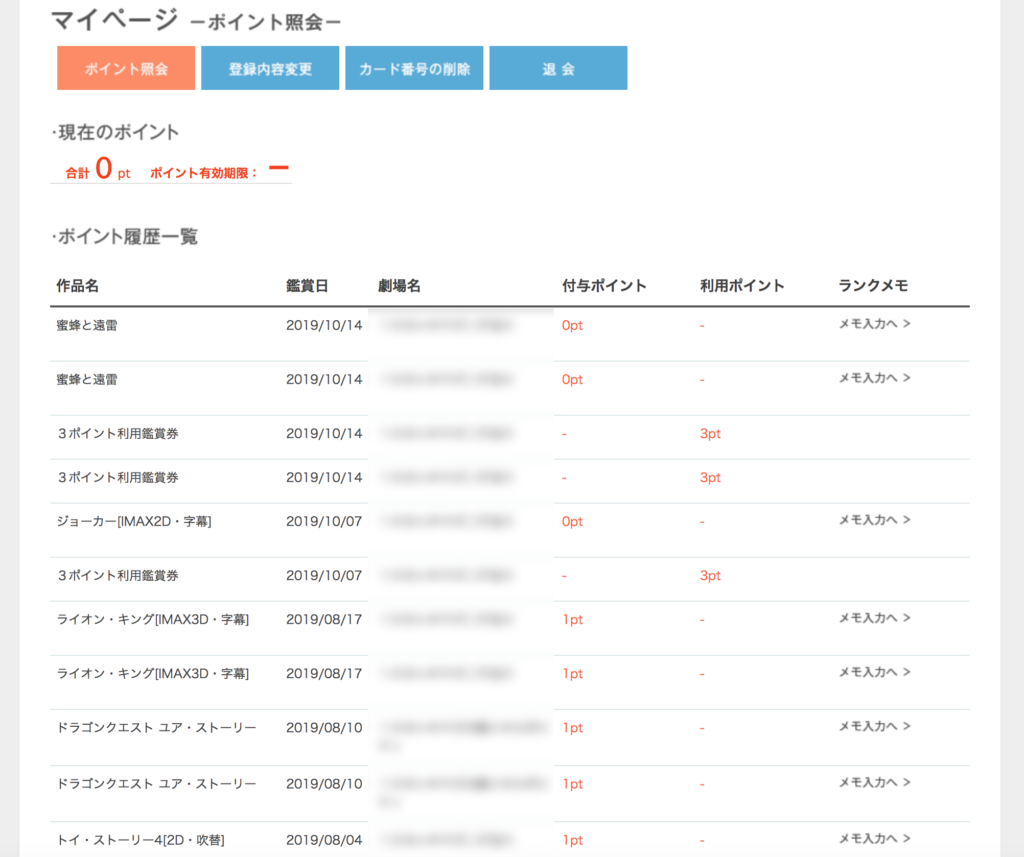
綺麗なテーブルになっており、そこまで量も多くないと思われますので、
あとはコピペしてexcelなどを経由してcsvファイルにすることもできますが、
処理の自動化や個人用のウェブサービス化を想定し、
この情報をpythonで取得していくことにします。
| python seleniumでのスクレイピング
pythonにはBeautifulSoupはじめ、
様々なスクレイピング用のパッケージがありますが、
今回はログインサイトでのスクレイピングのため、
記事にアクセスするだけではなく、ボタン操作などを行うことを想定し、
seleniumを用いてスクレイピングしていきます。
まずはseleniumの必要なパッケージをimportします。
(もしパッケージがない場合は、pip install selenium)
|
1 2 |
from selenium import webdriver from selenium.webdriver.common.keys import Keys |
次に、browserを定義します。
|
1 2 |
browser = webdriver.PhantomJS() browser.implicitly_wait(3) |
browserを準備できたら、
109シネマズのログインページにアクセスしてみます。
ログインページURL末尾は劇場によって異なりますが、
前述の通り、劇場は特に何も影響ないので、
適当に選んだもののURLを調べておきます。
※下記は、適当に東京・二子玉川を選択した場合の例
|
1 2 |
url_login = "https://cinema.109cinemas.net/cgi-bin/pc/login.cgi?tsc=T1" browser.get(url_login) |
無事にアクセスできているかは、
print(browser.page_source)で確認できます。
該当ページのhtmlのソースが表示されていれば、
正常にアクセスできています。
|
1 |
print(browser.page_source) |

次に、seleniumでログインしていきます。
現在ログインページにアクセスしておりますので、
ログイン入力フォームの、ID/PASS入力箇所の名前(div名/class名)を、
htmlソースから調べます。
ID入力フォームのdiv名が「id」、
PASS入力フォームのdiv名が「pw」ですので下記のようにすることで、
入力フォームのキーを入力し、ENTERを押す操作ができます。
|
1 2 3 4 5 |
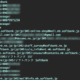
e1 = browser.find_element_by_id("id") e1.send_keys("*****(自分の109シネマズのアカウントID)") e2 = browser.find_element_by_id("pw") e2.send_keys("*****(自分の109シネマズのパスワード)") browser.find_element_by_id('pw').send_keys(Keys.ENTER) |
これでログインページへ遷移できますので、
mypageのURLに遷移して正しくログインできるか確かめてみましょう。
|
1 2 3 |
url_mypage = "https://cinema.109cinemas.net/cgi-bin/pc/logon.cgi" browser.get(url_mypage) print(browser.page_source) |
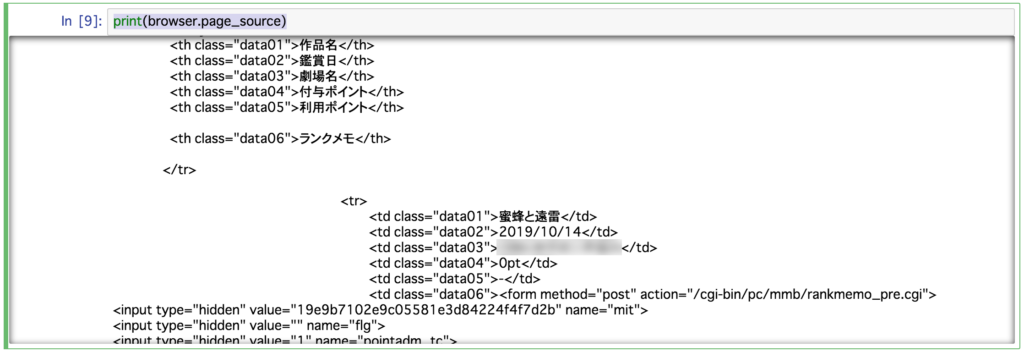
無事アクセスできているようです。
上記キャプチャの通り、各映画閲覧情報のclass名は下記となります。
「作品名」:data01
「鑑賞日」:data02
「劇場名」:data03
「付与ポイント」:data04
「利用ポイント」:data05
よって、例えば、作品名、鑑賞日一覧を取得したい場合、
下記の通りとなります。
※各要素をリストに格納しながら表示
|
1 2 3 4 5 6 7 8 9 10 |
titles = browser.find_elements_by_class_name("data01") dates = browser.find_elements_by_class_name("data02") title_list = [] date_list = [] for t,d in zip(titles,dates): title_list.append(t.text) date_list.append(d.text) print(t.text,d.text) |

無事データを取得できました。
せっかくなので、いろんな分析をしてみましょう。
| 取得した映画鑑賞データの前処理
取得したデータは、そのままでは扱いづらいため、
いくつか前処理が必要となります。
例えば、映画名に「2D・吹替」「IMAX2D」などの表記が
付与されておりますが、
今後、別のデータと結合することを考え、削除しておきます。
※あるいは別カラムで属性として持つことも有用かもしれません。
これらの記載は、時期によって表記ゆれしておりますので、
期間中の様々な表記に対応しておく必要があります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
title_list2 = [] for t in title_list: t = t.replace("[IMAX3D・字幕]","") t = t.replace("[IMAX2D・字幕]","") t = t.replace("IMAX3D[字]","") t = t.replace("[IMAX2D]","") t = t.replace("[2D・字幕]","") t = t.replace("[2D・吹替]","") t = t.replace("[字幕]","") t = t.replace("[吹替]","") t = t.replace("[IMAX次世代3D字幕]","") t = t.replace("[IMAX3D字幕]","") t = t.replace("IMAX3D字]","") t = t.replace("IMAX]","") t = t.replace("2D吹]","") t = t.replace("字]","") t = t.replace("IMAX3D[字]","") t = t.replace("吹]","") t = t.replace("2D字]","") t = t.replace("字]","") t = t.replace("2D","") t = t.replace(" ","") t = t.replace("・","") t = t.replace(":","") t = t.replace("/","") t = t.replace("…","") title_list2.append(t) print(t) |
また、鑑賞映画に「ポイント利用」が含まれておりますので、
削除しておきましょう。
※あるいは別カラムで支払い情報として持っておいてもよいかもしれません。
その他、友人と映画を観る場合、
複数のチケットをまとめて購入しているケースがあります。
よって重複したデータは削除しておきます。
ついでに今後の処理を考え、DataFrameに変換しておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import pandas as pd year_list = [] for d in date_list: year = d.split('/')[0] year_list.append(year) my_movie_df = pd.DataFrame( {'title': title_list2, 'watch_date': date_list, 'year': year_list, }) my_movie_df = my_movie_df.drop_duplicates() my_movie_df = my_movie_df[my_movie_df['title'] != "作品名"] my_movie_df = my_movie_df[my_movie_df['title'] != "3ポイント利用鑑賞券"] my_movie_df = my_movie_df[my_movie_df['title'] != "6ポイント無料券"] my_movie_df = my_movie_df[my_movie_df['title'] != "6ポイントチケット交換"] my_movie_df = my_movie_df.reset_index(drop = True) my_movie_df =my_movie_df.drop("index",axis=1) |
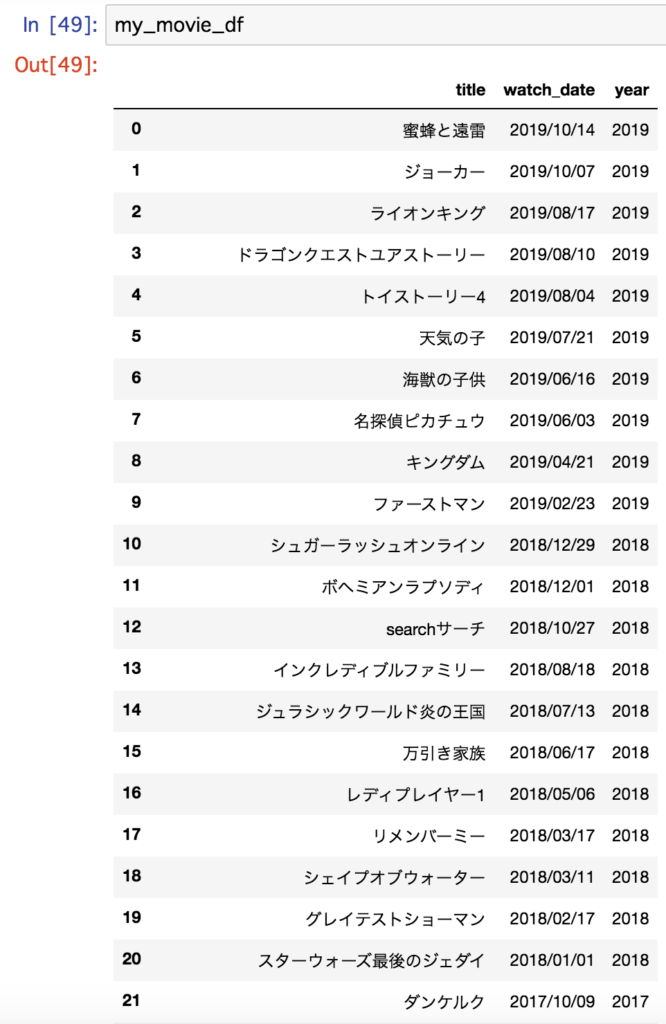
これで分析の準備は、ほぼできたのですが、
自分の映画鑑賞履歴だけですと、その客観的な評価ができません。
よって、今回は各映画の興行収入・レビューデータを紐付けておきます。
データソースは様々なサイトがありますが、
年代ごとにデータが綺麗にまとまっている「ピクシーン」さんは、おすすめです。
109シネマズと同様の手順で、サイトから情報を取得し、
DataFrameにしておきましょう。
(ログインしなくてよいため、むしろ簡潔に行えます。)
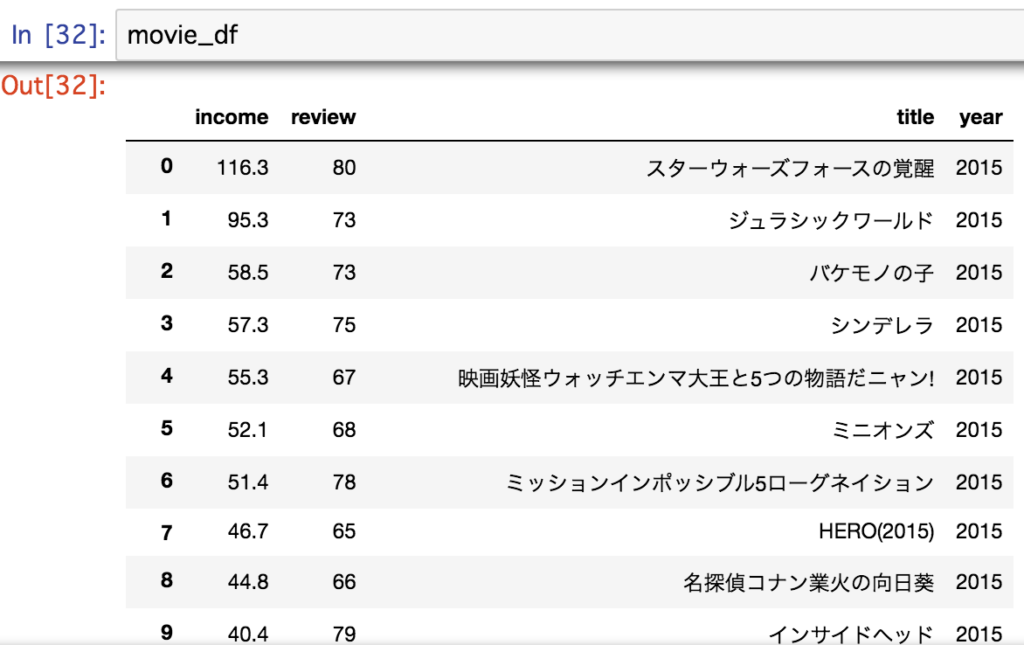
このデータを、先ほどの自分の映画鑑賞履歴と紐付けておきます。
紐付けの際は、タイトルの部分一致、および年代でマッチしたものに
しておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import re my_df_review = [] my_df_income = [] for i,my_row in my_movie_df.iterrows(): tmp_review = -99 tmp_income = -99 for j,row in movie_df.iterrows(): if (re.sub('[1-9]', '', my_row.title) in re.sub('[1-9]', '', row.title) ) and (int(my_row.year) == row.year): tmp_review = row.review tmp_income = row.income break my_df_review.append(tmp_review) my_df_income.append(tmp_income) my_movie_df2 = pd.concat([my_movie_df, pd.DataFrame(my_df_review)], axis=1) my_movie_df2 = pd.concat([my_movie_df2, pd.DataFrame(my_df_income)], axis=1) my_movie_df2.columns = ["title","watch_date","year","review","income"] |
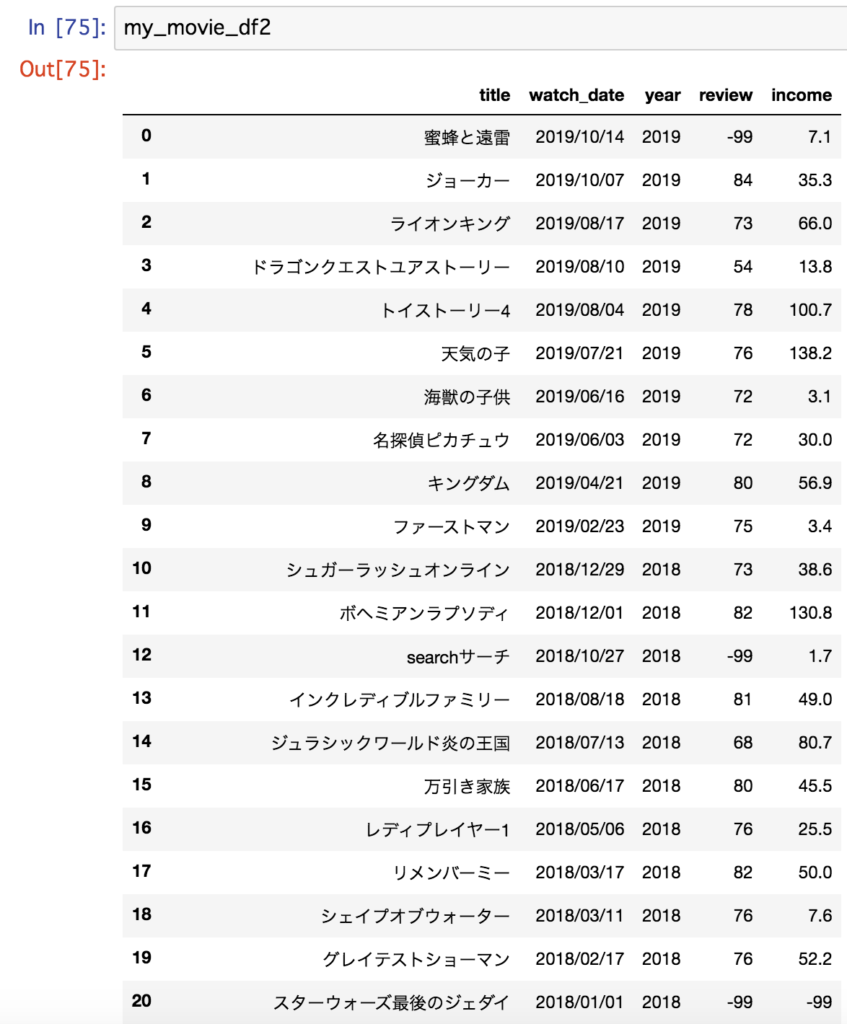
これで、自分の映画鑑賞履歴、年代ごとの興行収入・評価データ、
およびそれらを紐付けたデータ、を生成できました。
では、いよいよデータの中身を集計していきます。
| 自分の映画鑑賞の変遷を見てみる
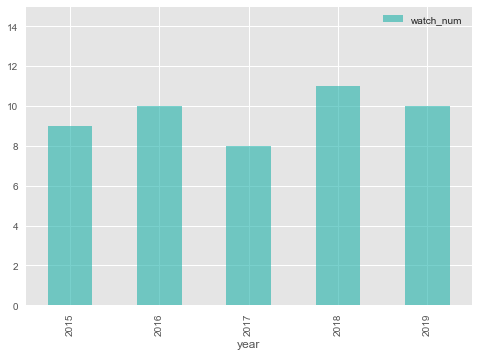
まずは、映画鑑賞本数の推移を見てみます。
例年、私は10本前後の映画を観ているようです。
集計時点の10月時点ですでに10本いっておりますので、
今年は過去5年で一番多くの映画を観た年になりそうです。
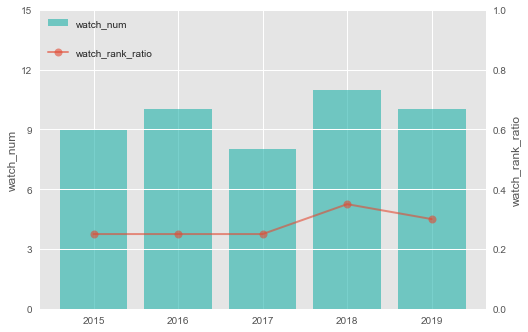
次に、観た映画が、その年の興行収入Top20に入っていた割合をみてみます。
例年3割ほどで、意外にその年のヒット映画は、
そこまで観ていないのかもしれません。
※いわゆるマーベル系などを観ていません。
今年でいうと「海獣の子供」、去年は「search/サーチ」などが、
その年のTopヒット映画ではないものの鑑賞した映画、に該当します。
どちらも素晴らしい映画でした。
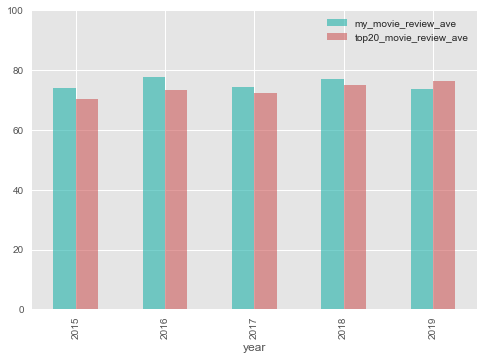
では、実際に観た映画の評価はどうでしょうか。
各年のTop20映画の平均レビュー点数と、
自分が観た映画の平均レビュー推移は下記となります。
なんと、今年以外は、Top20映画よりもレビュー点数が高くなっております。
つまり、観るべき映画を選別できてるわー。(急にミサワ風にドヤる人。)
ではなぜ、今年は例年と異なり、Top20映画よりも自分の観た映画の、
平均レビュー点数が低かったのか。
それは「ドラゴンクエスト ユア・ストーリー」の影響が大きいです。
多くは語りません。
私がドラクエ映画を観るときには、
すでにネットで多くのクチコミがありましたが、
怖いものみたさで観たら、怖い思いをしました。
以上、映画鑑賞履歴を取得していきました。
みなさま、良き映画ライフを。
関連記事:



人気記事: