Article

・Kaggleやデータ分析初学者向けのチュートリアル解説本を執筆しました。本記事とあわせてご参照くださいませ。
『Pythonで動かして学ぶ!Kaggleデータ分析入門』

・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
はじめに
今回はKaggle CIBMTRコンペこと、「CIBMTR – Equity in post-HCT Survival Predictions」の参戦振り返り記事となります。 人種ごとのHCT移植後生存期間を予測する、いわゆる生存時間分析コンペでした。特徴量エンジニアリングよりもターゲットエンジニアリングが肝になるコンペでした。結果はPublicから69位Shakedownの111位となりました。本稿ではコンペの概要および上位解法などを振り返っていきたいと思います。

| (1) CIBMTRコンペの概要
本コンペでは、同種造血幹細胞移植(HCT)を受ける患者の生存率予測モデルの精度を向上させることが求められました。イベントフリー生存(efs)および生存時間(efs_time)を対象とするいわゆる生存時間分析となります。特に、社会経済的要因、人種、地理的要因に関連する予測の格差を改善することが重要な課題となっていました。
efs、efs_timeの分布は下記のようになっており、これらをlinelinesなどのライブラリを用いる、あるいは独自に変換して、いかに予測しやすいタスクにするかの工夫が求められました。

efsごとのefs_timeの分布

efsとefs_timeからkaplanMeierで1つのターゲットに変換したもの(efsごとに色分け)
評価指標はStratified Concordance Index(C-index):モデルの予測精度と公平性を評価する指標で、人種ごとの精度のばらつきを抑えることが求められました。

デーは実際のデータをもとにSurvivalGANでの合成データが与えられ59種類の変数(患者・ドナーの年齢、性別、人種、疾患状態、治療内容など)が含まれていました。合成データであるということもあり、年齢の不自然な分布などの問題が報告されていましたが主催者側も検証を経て結果的にこの点が本コンペの指標においてはクリティカルな問題にはなっていなかったようです。

(上記discussionより転載)
| (2) 本コンペの取り組み
本コンペで重要だと考えていたことは以下のことでした。
・追加データの生成
本コンペのデータは合成データでありSurvivalGANで生成されていることが明示されていました。そのため同様のアプローチでデータ拡張ができると思われます。しかし実際には提供されているデータがすでに合成データであるため、どのようにデータのフィルタリングをしたり整形したりしてもSurvivalGANで生成したデータを元にさらにSurvivalGANで生成することになり学習精度が悪化する結果にしかなりませんでした。コンペ中、都度試したものの中盤以降は切り捨てました。
・ターゲットエンジニアリングの工夫
このコンペはイベント有無のefs、イベント発生までの期間(efs_time)の2つがターゲットとして与えられていたため、これらを何かしらの方法で一つにまとめて回帰タスクとして解くというアプローチが序盤からChrisはじめ多く共有されていました。たとえばlifelinesパッケージではKaplanMeierなどの様々な変換です。これらの変換だけでは精度として不十分であり、この変換に合わせて平方根変換やboxcox変換、スケーリングなどが精度向上に寄与したため、様々なターゲットエンジニアリングに序盤から終盤まで最も多くの時間と手間をかけました。
・コンペ指標に合わせたクロスバリデーション
評価指標が人種ごとに予測精度に偏りがないようにする必要があったことからシンプルに考えるとrace_group(人種)でStratifiedKFoldすることが考えられます。しかし与えられたデータがすでに各人種均等に生成されたデータであったため、人種ごとの公平性に寄与するさらなるCVの切り方を模索し続けました。最終的には移植時の年齢であるage_at_hctという変数をbin化したage_binという特徴量を用いてStratifiedKFoldしました。これは各人種で微妙に年齢分布が異なっていたこと、年齢が予測重要度が高かったこと、前述の通り年齢には不自然な分布があったためbin化したほうがよさそうだと思ったことからでした。結果的にこれはうまくいきました。このアプローチを採用後も様々なCVを模索し続けました。
・前処理/後処理および学習時の工夫
ターゲットをefs、efs_timeから1つの目的変数にまとめるにしても、efsの有無をどのように加味するかは前処理として様々な工夫がコンペ中に議論されていました。たとえばKaplanMeierで変換したターゲットをefs=0/1の値に応じてシフトして分離し予測しやすくするなどです。しかしefs=0とefs=1の場合でも比較対象になり得るペアがあることから単純にシフトして切り離すよりもefs=0/1ごとにある係数をかけて調整するほうが良いと思い最適化したところそれなりに精度が向上しました。
また予測したあとの結果に対する後処理として、efs=0/1を予測する分類モデルを学習し、その予測efsに応じて回帰モデルの予測結果をシフトする後処理を用いたコードがコンペ中盤にpostされました。こちらも前述の理由からシフトよりも係数をかけて調整する方が精度改善につながりました。
さらにコンペ終盤に、モデル学習時にefs_timeの長さに応じてsample_weightを変える処理を思いつき、精度改善につながりました。
その他、特徴量エンジニアリング、欠損値処理など様々なことをコンペ序盤〜中盤に試したものの、合成データであるためか、なかなか精度改善につながらず、コンペ中盤以降は切り上げて上記のターゲットエンジニアリングと前処理/後処理などのチューニングに時間を割きました。
下記が最終的な私のアプローチの概要となります。
(step.1) efs_timeをyear_hctから考えられうる現実的なキャップで補正(データ生成時からyear_hctが1年前時点ならefs_timeは12か月以内でないとおかしい)。
(step.2) いくつかのカテゴリ変数で出現頻度が少ない選択肢をまとめる。
(step.3) efs、efs_timeをKaplanMeierで1つの指標にまとめたあとefs=0/1に応じて係数をかけて調整。
(step.4) 上記で算出したリスクスコアをさらに平方根変換あるいはboxcox変換などにかけた上で0-1にスケーリング(複数パターンで変換しアンサンブル)。
(step.5) 変換後のターゲットをクロスエントロピーで学習。学習時にはefs_timeでsample_weight変える。
(step.6) cat/lgb/xgb/tabm/mlpなどで学習し各モデルの予測値を標準化(rankdataなどで順位化するのではなく)してnelder-meadでアンサンブル。
様々なアプローチがそれなりにうまくはまり、publicでコンペ期間残り1か月時点で3位だったときには、かなり夢を見ました。しかし冒頭で述べたとおり最終盤ではスコアを伸ばすことができず結果的に111位でSilverとなり、Gold圏とは大きな差を感じたコンペでした。

| (3) 上位ソリューション
publicでefs、efs_timeをlifelinesパッケージを用いてひとつのグループにまとめる手法が公開されていたことから多くの参加者がそのアプローチをとっていましたが、上位陣はefsの分類、efs_timeの回帰という2stepで解く手法がメインでした。しかしこの手法は工夫しないと精度が出ず、上位陣でもefsの分類予測結果とefs_timeの回帰予測結果をどのように組み合わせるかはチームによって異なりました。例えば1位解法は下記のようなアプローチでした。
・1位解法:
– efsを分類モデルで学習
– efsごとに正規化したefs_timeの順位を回帰モデルで学習
|
1 2 |
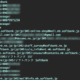
efs_time_norm[efs == 1] = efs_time[efs == 1].rank() / sum(efs == 1) efs_time_norm[efs == 0] = efs_time[efs == 0].rank() / sum(efs == 0) |
|
1 2 3 4 5 6 7 8 9 10 |
def model_merge(Y_HAT_REG,Y_HAT_CLS,a=2.96,b=1.77,c=0.52): ''' Y_HAT_REG and Y_HAT_CLS need be scaled to 0~1 a,b,c need to be tuned with optuna ''' y_fun = (Y_HAT_REG>0)*c*(np.abs(Y_HAT_REG))**(b) x_fun =(Y_HAT_CLS>0)*(np.abs(Y_HAT_CLS))**(a) res = (1-y_fun)*x_fun+y_fun res = pd.Series(res).rank()/len(res) return res |
上位解放が公開された直後、「efsの分類とefs_timeの回帰をそれぞれ2stepで解いて組み合わせる」という斜め読みだけをして自分のbaselineコードでも試してみましたが全くうまくいきませんでした。つまりこれ自体はアイデアではなく、そのあとの組み合わせ方がアイデアなのだと思います。ゆえにやはりこのコンペはターゲットエンジニアリングコンペだったのだと思います。
なお、このコンペでは終盤に後処理としてefsの予測結果に応じて回帰の予測結果をシフトする処理、特に特定人種に対して調整する必要性がdiscussionで示唆されていました。そして実際にCV・PublicLBでは精度向上につながったものの、それらの処理はPrivateLBでは大きな精度悪化をもたらし、一部の参加者のShakedownにつながる要因だったようです。
| (4) おわりに
本コンペの敗因は主に下記2つを出来ていなかったことだと思います。
・コンペの土台となる論文を読み込む
今回、データは生成データであり、SurvivalGANを用いていることが明示されていました。2位解法でも触れられていましたが、そのデータ生成背景からefsとefs_timeを別々に予測して2stepで解くというアプローチにたどり着けるはずです。今回のコンペのようにデータ生成に関するもの以外でも、今後コンペ主催者が明示しているコンペの背景に関する論文を深堀しない理由はなく、まずは目を通すことを必ず初手にしようと思いました。そして今なら様々なLLMツールを用いてその手順を高速に効率化することができますのでそのフローを整えておこうと思いました。
・正しいはずのアプローチには様々なパラメータ設定ふくめ時間をかけて粘る
UMコンペのときの反省と全く同じですが、少し異なる視点から振り返ると今回このコンペではKaplanMeier含めてlifelinesライブラリの様々なターゲット変換がコンペ中に投稿されていました。一方でefs、efs_timeをそのまま用いた手法は(pairwise以外)ほぼ投稿されていませんでした。しかし蓋を開けると上位陣はefs、efs_timeを2stepで解くというアプローチが主流でした。ここで重要な点は、efs、efs_timeをそのまま用いて2stepで解くという手法は比較的思いつきやすいものの、実際に実装して高精度を出すにはこの2stepをどのように組み合わせるか様々な工夫が必要であったことです。つまり2stepでやると思いついて試して精度が悪かった場合に、このアプローチはダメだと切り捨てるのではなく、なぜこのアプローチで精度が出ないのか、どうしたら精度が出るようになるのか結果から粘り強く考察することが必要だと思いました。しかもそれはコンペ中では誰にも言及されていないとしても、です(言及されていないからこそ?)。
以上、CIBMTRコンペの振り返りとなります。
関連記事:






人気記事: