Article

・Kaggleやデータ分析初学者〜中級者向けの実験管理本を執筆しました(共著)。本記事とあわせてご参照くださいませ。
『目指せメダリスト!Kaggle実験管理術 着実にコンペで成果を出すためのノウハウ』

・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
はじめに
今回はKaggle CMIコンペこと、「CMI – Detect Behavior with Sensor Data」の参戦振り返り記事となります。 腕の甲に装着したデバイスからの加速度センサなどのデータからgestureを分類するコンペでした。cv/public/privateがそれなりに連動していて取り組み始めやすかったものの、スコアがある一定以上になると連動が不安定になることや、とあるトリックに気づけるかどうかで大きくスコアに差が出るコンペで、最後まで試行錯誤し続けたコンペでした(結局トリックには気付けませんでした)。結果public35位、private33位でsilverメダルとなりました。本稿ではコンペの概要および上位解法などを振り返っていきたいと思います。
| (1) CMIコンペ2025の概要
このコンペは、BFRB(Body-Focused Repetitive Behaviors)と呼ばれる髪を抜く、皮膚をむしる、爪を噛むといった、自傷行動を高い精度で検出するモデルを開発することです。Child Mind Instituteは、これらの行動を検出するために、Heliosという手首装着型のウェアラブルデバイスを開発しました。このデバイスには、加速度(acc)や角度(rot)など動きを捉える”IMU(慣性計測ユニット)”に加え、体温を測る”thm”センサーと、近接を検知する”ToF”(Time-of-Flight)センサーが搭載されていました。これらの多様なセンサーデータを活用して、BFRBとそれ以外の日常的な行動(例:食事、タイピングなど)をいかに正確に区別できるかが求められました。
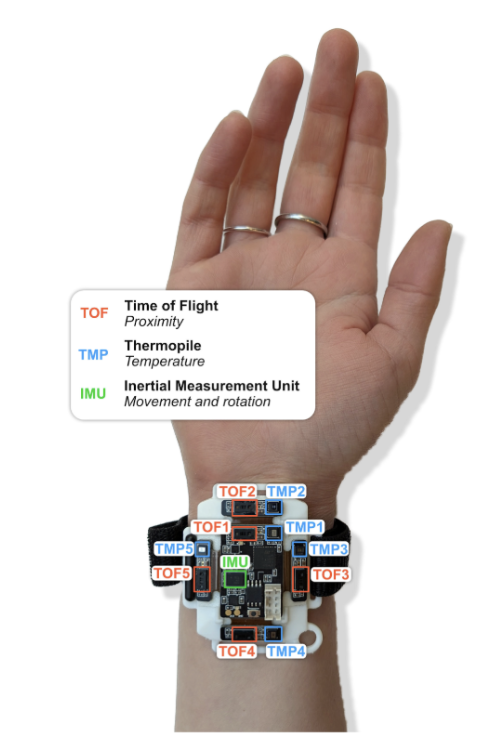
(コンペ概要ページからのデバイス説明画像より)

(各シーケンスにおけるacc(mag)/rotの可視化の例。EDA notebookより)
評価指標は以下の2つの要素を均等に重み付けしたmacroF1です。
– ジェスチャがターゲット型か非ターゲット型かを判断するbinaryF1。
– 各ジェスチャに関するmacroF1(ただし非ターゲットはすべて単一の非ターゲットクラスに集約される)
またtestデータでは半分のデータがimuのデータのみしか含まれていないことが明言されていました。
| (2) 本コンペの取り組み
本コンペの私のアプローチは下記のようなものでした。
前処理
– 利き手の違いの吸収
– 欠損値処理のち、robustscalerでscaling
– transitionフェーズは最後の100サンプルに限り、gestureに集中させて学習
モデル
– imu/allに分けて学習
– Conv1D、squeezeformer、LSTM、GRUを組み合わせた構造
– (利き手のちがいを十分に処理しきれていないと感じていたため)利き手情報もモデルに組み込む
– さまざまなdata aug。時間軸の伸縮やノイズ、3D回転やcutmix/mixupなど
多段階アンサンブル
– 階層的多数決投票
– まず複数のモデルで意見が一致しているかを確認し、その一致度次第でstackingモデルの重みを調整した上で多段階投票
上記の処理はコンペ期間中、順次追加していき、途中あまり停滞することなく順調にスコアを伸ばすことができました。
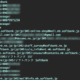
特に最後の多段階投票がユニークな点で大きくスコアを伸ばすことができました。(この処理を取り入れた時点で0.858→0.864)このコンペではモデルの出力結果の平均よりも多数決のほうが精度がよいというdiscussionが多く報告されており、実際に私の環境でもそうだったのですが、それならばもっと良いやり方があるのではと思い、コンペ指標も鑑みながら試行錯誤した結果となります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
def hierarchical_vote_dynamic_panel( probs_list: list, # ベースモデル群の予測リスト stacking_probs: np.ndarray, # Stackingモデルの予測 (形状: 5, 18) target_idx_list: list, non_target_idx_list: list, *, # --- 動的重み付け用のパラメータ --- high_consensus_threshold: float = 0.8,#0.7, low_consensus_threshold: float = 0.4, high_consensus_weight: int = 1, mid_consensus_weight: int = 4, low_consensus_weight: int = 5, k_of_n: int = 8, t_target: float = 0.45, consensus_k: int = 3, ): """ ベースモデルの合意度に応じて、5つのスタッキングモデルの 重みを動的に変更し、階層的投票を行う関数。 """ # ============================================================================== # ステップ1:ベースモデルの合意度に基づき、Stackingパネルの重みを動的に決定 # ============================================================================== base_model_count = len(probs_list) # ベースモデル群の合意度を計算 base_hard_preds = [int(np.argmax(p)) for p in probs_list] counts = Counter(base_hard_preds) if not counts: top_votes_ratio = 0 else: top_votes = counts.most_common(1)[0][1] top_votes_ratio = top_votes / base_model_count # 合意度に応じてStackingの重みを決定 if top_votes_ratio >= high_consensus_threshold: stacking_weight = high_consensus_weight elif top_votes_ratio >= low_consensus_threshold: stacking_weight = mid_consensus_weight else: stacking_weight = low_consensus_weight # stacking_probs (5, 18) を5つの個別の予測リストに変換 stacking_predictions_as_list = [p for p in stacking_probs] # 動的に決定した重み回数だけ、5つの専門家の意見をリストに追加 # 例:weight=3なら、5つの予測が3回ずつ、計15個の予測が追加される final_probs_list = probs_list + stacking_predictions_as_list * stacking_weight # ============================================================================== # ステップ2:動的に作成したリストを使い、階層的投票を実行 # ============================================================================== M = len(final_probs_list) C = final_probs_list[0].shape[-1] tgt = np.array(target_idx_list, dtype=int) ntt = np.array(non_target_idx_list, dtype=int) # ---------- 1) Binary ゲート(TargetかNon-Targetか) ---------- votes_for_target = 0 hard_preds = [] for p in final_probs_list: p = np.asarray(p, dtype=np.float64) p = np.clip(p, 1e-12, 1.0); p /= p.sum() hard = int(np.argmax(p)) hard_preds.append(hard) p_target = float(p[tgt].sum()) vote_target = (p_target >= t_target) or (hard in tgt) votes_for_target += int(vote_target) # ---------- 2) Non-Target 決定(ゲートがNon-Targetの場合) ---------- if votes_for_target < k_of_n: hard_nt = [h for h in hard_preds if h in ntt] if len(hard_nt) > 0: cnt = Counter(hard_nt) top_nt, top_votes_nt = cnt.most_common(1)[0] else: top_nt, top_votes_nt = None, 0 if top_votes_nt >= consensus_k: return int(top_nt) else: # 低合意時は、スタッキングの「総意(平均)」を採用 avg_stacking_prob = np.mean(stacking_probs, axis=0) idx_local = int(np.argmax(avg_stacking_prob[ntt])) return int(ntt[idx_local]) # ---------- 3) Target 決定(ゲートがTargetの場合) ---------- else: hard_tg = [h for h in hard_preds if h in tgt] if len(hard_tg) > 0: cnt = Counter(hard_tg) top_tg, top_votes_tg = cnt.most_common(1)[0] else: top_tg, top_votes_tg = None, 0 if top_votes_tg >= consensus_k: return int(top_tg) else: # 低合意時は、スタッキングの「総意(平均)」を採用 avg_stacking_prob = np.mean(stacking_probs, axis=0) idx_local = int(np.argmax(avg_stacking_prob[tgt])) return int(tgt[idx_local]) |
また今回から開発環境をVSCodeからCursorに変えたことでコーディングの効率は相当向上しました。ただし、Cursorが全自動で問題ないコードを書いてくれるということはなく、こちらからそれなりに意図を持った指示が必要かつ都度修正が必要でした(その修正はCursor内で完結できることも多いですが)。EDAもCursorで自動で行うことを試みたのですが初歩的な分析や考察に留まってしまい結局自分でやりました。この点はEDA用のプロンプトや関数を整理しておくなど、より良いやり方を模索できる気がします。
終了1週間前にkssさんにチームマージをお誘いいただき、2人チームとして参加することにしました。自分はかなりsubを使う方なので終了2,3週間前くらいのマージがちょうど良いと思います。kssさんはpytorch、私はkerasのコードだったこともありコードのマージに少し戸惑いましたが、その過程で自分のプログラムのバグにも気付くことができ、それぞれのソロの結果を大きく上回るスコアを出すことができました。最終的にはimuはkssさんベースに私のモデルの予測をアンサンブルした上で上記の私の多段階投票、allは私の予測をベースにkssさんの予測をアンサンブルした上で多段階投票しました。
このコンペは終了4日前に上位陣の一部が大きくスコアを伸ばしたことでleakあるいは何かしらのトリックがあるのではと気付き始め、kssさんと私もさまざまな分析を試みたのですが結局大きな精度向上につながるようなもの(後述するトリック)には気付けませんでした。
(上位陣のトリックに戸惑う我々)
結果、一部チームでshakeがあったもののpublic35位、private33位で着地しました。ほぼshakeはなく堅実なアプローチではあったと思います。
| (3) 上位ソリューション
上位陣のソリューションを分析すると、いくつかの共通する戦略と、スコアを大きく伸ばした独自の工夫があるようです。
[共通する戦略]
・多様なモデルのアンサンブル
・imu-onlyとall dataでモデルを分ける(さらに細かく分けるチームもあり)
・左利きのデータを右利きのデータに揃える反転処理
・後処理の「トリック」によるスコア向上
前半3つのアプローチは私たちのチームもできていたのですが、それでも上位ソリューションを見るとモデルの分け方はもっと工夫できたと思いますし、反転処理もより丁寧な処理ができたと感じます。また最後の後処理のスコア向上ができませんでした。
このコンペでは、「gesture18パターン、orientation4パターンのうち51パターンしかデータ中に存在しないこと、さらにbehavior2パターンを組み合わせて102パターンが1つづつしかsubjectごとに存在しない」という制約がありました。これは「各subjectにおいてgesture/orientationの組み合わせを2回までしか行わない」という制約と同じです。この制約に気付いて予測結果を最適化問題として調整する後処理が非常に有効でした。さらには一部ユーザへの上下反転処理という別のトリックもありました。
[各チームのアプローチ] ※解釈違いあるかもしれません。詳細は下記のチーム名からのリンクをご確認ください。
| 順位 | チーム名 | 主要モデルアーキテクチャ | 主要な前処理・特徴量エンジニアリング | トリック・後処理 |
|---|---|---|---|---|
| 1位 | Devin | Ogurtsov | zyz |
アンサンブル他、IMUとALLモデルのブレンド、TOFのみのモデルのブレンド | 利き手反転、Mixup | ヒューリスティックフィルタリング: (ジェスチャー, 向き)ペア毎の予測を制限 |
| 2位 | daiwakun |
1D-CNN, Phase-Aware Attention | 複合ターゲット、利き手反転、フェーズに合わせたMixup | 同時確率最大化(重複なし制約下) |
| 3位 | ln, yu4u, Theo, minerppdy |
アンサンブル (Transformers, MaxViT, ConvNeXt, EfficientNet) | クォータニオンベースのAugmentation、複合損失関数、物理ベース特徴量 | ヒューリスティックフィルタリング: (ジェスチャー, 向き)ペア毎の予測を制限 |
| 4位 | dott |
アンサンブル (CNN-Attention, BERTベース) | 複合ターゲット、利き手反転 | 最尤推定最適化(重複なし制約下) |
| 5位 | have fun |
被験者ベースTransformer, CNN/RNN | シーケンス間関係学習のための被験者単位バッチ処理 | 被験者ごとの利用可能な履歴データ量に基づくモデル選択 |
| 6位 | Jack (Japan) |
カスタム1D-CNN (入力が異なる2パターン、異なるランダムシード50個によるデータセットでの100個のNN出力平均) | 高度な利き手補正 | 上下逆デバイス補正 |
金圏の上位陣のアプローチはどれも行えていませんでした。また似たようなアイデアを試したもののうまくいかずに断念したものもありました。いわゆる正攻法なものからハック的なものまで含めて、どのような決め手で勝負することができそうか、他とは違う自分たち独自の差分で勝因になりそうなことは何かを取り組みながらでいいので最後には発見する必要があると強く思いました。
| (4) 反省・今後に向けて
本コンペの敗因は2種類のトリックに気付けたかどうかでした。実際どちらかのトリックに気付けていれば金圏に入れていたようです。
終盤、上位陣が明らかに異常なスコアの上がり方をしたことで、自分たち含めて多くの参加者が何かしらのトリック(あるいはリーク)があることは気付いたものの、肝心のそれが何なのかが最後までわかりませんでした。
振り返って、どうしたらコンペ中に(上位陣のスコア上昇前にでも)気付けただろうかと考えるに、いくつかの視点があると思います。
・全てのデータの活用方法を考える
まずは与えられた全てのデータについて本当に活用の方法はないのか考えるということだと思います。今回trainデータに含まれているもののtestデータには含まれていないカラムがいくつかありました。targetである「gesture」のほかに「sequence_type」「orientation」などです。このうち「orientation」は容易に予測することが可能で(予測精度95%のモデルを作ることが可能)この情報をうまく活用することが肝でした。まずここに辿り着けていれば大幅なスコア向上トリックまでいけなくてもさらなる上位進出は可能だっただろうと思います。trainデータにはあってtestデータにない情報は予測できないか全て取り組んでみる、そのデータがあると何ができるか考えてみることが重要だと思いました。
・targetの分布についてあらゆる角度から分析する
非常に基礎的なことだと思いますが、targetであるgestureの単純な分布を可視化することに加え、特定属性ごとに偏りが生じていないかは大前提チェックする必要があります。その上で「もしこのtargetに何かしらの制約があるとしたらどのような制約があり得るか」と疑って、さまざまなカラムを組み合わせて分析することが必要でした。今回の場合、subjectとorientationの組み合わせを分析するべきだったのですが、もしかしたらより良いCVの切り方を求める中で気付けた可能性もありますし、targetの予実差を分析する過程でも気付けたかもしれません。しかしここでもとにかく「orientation」というカラムを見落としているとtarget制約のトリックに辿り着けなかったため、突き詰めると一つ目の全てのデータの活用方法を考えるということに立ち戻ります。
・異常なデータは除外するのではなくtestデータにも同様に異常なデータがあると仮定する
今回、trainデータにデバイス装着が上下逆になっているsubjectが2名のみ存在していました。この2つのsubjectは多くの参加者が学習・検証から除外していました。(我々のチームは学習のみから除外)しかし同様のデータはpublic dataでは存在しなかったもののprivate dataには存在しており、subjectごとにデバイス装着が正しいかを予測し、反転処理を入れることで大幅にスコア向上ができるようでした。こちらのトリックでも我々のチームは金圏内に入ることができたため、むしろ悔しさとしてはこちらになぜ気付けなかったのかという気持ちの方が強いかもしれません。とにかく与えられたデータに誤りやイレギュラーなデータはないかチェックすること、trainに存在するデータの異常はtestでも起こり得ると仮定し、あらゆるケースを想定した処理を行うことが必要だと思いました。
上記に加えて、これまでの他のコンペでも同様ですが、金圏にたどり着くためにはそもそもコンペの取り組み方、スケジュールにも問題があるかもしれません。これまでもそうですが終盤では残りsubmit数の制約もあり、モデルの改善ではなくアンサンブルという手堅いスコア向上を狙うことが多かったのですが、最後の最後まで一発逆転の手を模索し続け、時にはアプローチを抜本的に変える勇気が必要だと思います。もっというと、最初にEDAを徹底的に丁寧に行うことはもちろん、最終盤においても、もう一度EDAをやり直して、予実差などから新しい仮説を模索し続けることが必要だと思いました。
本記事執筆時点でsilver9枚、bronze9枚、次こそはgoldを目指していきたいです。以上、CMIコンペ2025の振り返りとなります。
関連記事:






人気記事: