Article
・Kaggleやデータ分析初学者向けのチュートリアル解説本を執筆しました。本記事とあわせてご参照くださいませ。
『Pythonで動かして学ぶ!Kaggleデータ分析入門』

・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
はじめに
今回はPUBGコンペこと、「PUBG Finish Placement Prediction」の参戦振り返り記事となります。
本コンペはメダル付与対象ではない、いわゆるplayground(チュートリアル/リサーチ)コンペとなりますが、大人気オンラインゲーム、PUBGの数万試合のプレイデータの解析コンペであることと取り組みやすいテーブルコンペであったことから、他のチュートリアル/リサーチコンペよりも賑わっていたように思います(参加者1,534チーム)。実のところ、私自身もゲーム配信実況をするほどにはゲーマーであるため、本コンペに熱中いたしました。
結果は振るわなかったものの本記事では本コンペの取り組みや上位ソリューションを振り返っていきます。
目次
1) PUBGとは
2) 本コンペのゲームプレイデータ
3) 本コンペの特徴と取り組み
4) 余談1:パイプライン構築について
5) 余談2:EDA/チーターと回線落ちについて
6) 結果と上位ソリューション
7) おわりに
1) PUBGとは
2) 本コンペのゲームプレイデータ
3) 本コンペの特徴と取り組み
4) 余談1:パイプライン構築について
5) 余談2:EDA/チーターと回線落ちについて
6) 結果と上位ソリューション
7) おわりに
| (1) PUBGとは
PUBGとは、いわゆる、ここ数年人気のバトルロイヤル型の代表的なゲームとなります。バトルロイヤル型ゲームとは100人のプレイヤーが、フィールド内を移動しながら、武器や防具、回復アイテムなどを入手して敵をキルし、最後のひとりになった人が勝ち、というスタイルのゲームとなります。PUBG以外では、Fortniteも有名ですし、最近ではApex legendsが話題です。PUBGではsoloという一人プレイのほか、duo、squadといったチーム戦も用意されております。チームプレイの場合、味方と協力して他のチームをすべて倒せば勝ちとなります。
| (2) 本コンペのゲームプレイデータ
本コンペではPUBG APIで収集された47,965試合分の440万IDのtrain dataのゲームプレイログを解析し、test dataの20,556試合ごとの各プライヤーの最終順位を予測する、というコンペとなります。(この時点で楽しそうと思いませんか?)目的変数は順位そのものではなく順位%(1が最高順位、0が最低順位)を予測し、評価指標はmae(平均絶対値誤差)となります。
| レコード数 | データ中の試合数 | |
| train data | 4,446,966 | 47,965 |
| test data | 1,934,174 | 20,556 |
与えられた28個のパラメータは下記となります。
| winPlacePerc | 予測する目的変数。勝利順位 |
| matchId | 試合ID |
| matchType | 試合タイプ(“solo”、”duo”、”squad”など) |
| numGroups | その試合におけるグループ数 |
| maxPlace | その試合における最下位順位 |
| matchDuration | その試合が終わるまでの秒数 |
| groupId | グループID |
| Id | プレイヤーID |
| kills | キル数 |
| killStreaks | 連続キル数 |
| killPoints | キルベースのランキング |
| killPlace | その試合におけるキル数順位 |
| longestKill | キルしたプレイヤーとの最長距離 |
| DBNOs | ノックアウトした敵の数 |
| assists | キルアシスト数(自分がダメージを与えてチームメイトがキルした数) |
| headshotKills | ヘッドショットでのキル数 |
| damageDealt | 与えたダメージ数(自傷ダメージは含めず) |
| boosts | ブーストアイテム使用数 |
| heals | 回復アイテム利用数 |
| weaponsAcquired | 武器入手数 |
| revives | ノックアウトされたチームメイトを蘇生した数 |
| walkDistance | 歩行移動距離 |
| rideDistance | 乗り物に乗って移動した距離 |
| roadKills | 乗り物からキルした数 |
| swimDistance | 水泳距離 |
| teamKills | チームメイトをキルした数 |
| vehicleDestroys | 乗り物を破壊した数 |
| rankPoints | プライヤーランキング |
| winPoints | 勝利数ベースのランキング |
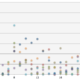
目的変数である「winPlacePerc」(最終順位の%表示)含む、各変数とそれ以外の値との相関は下記となります。
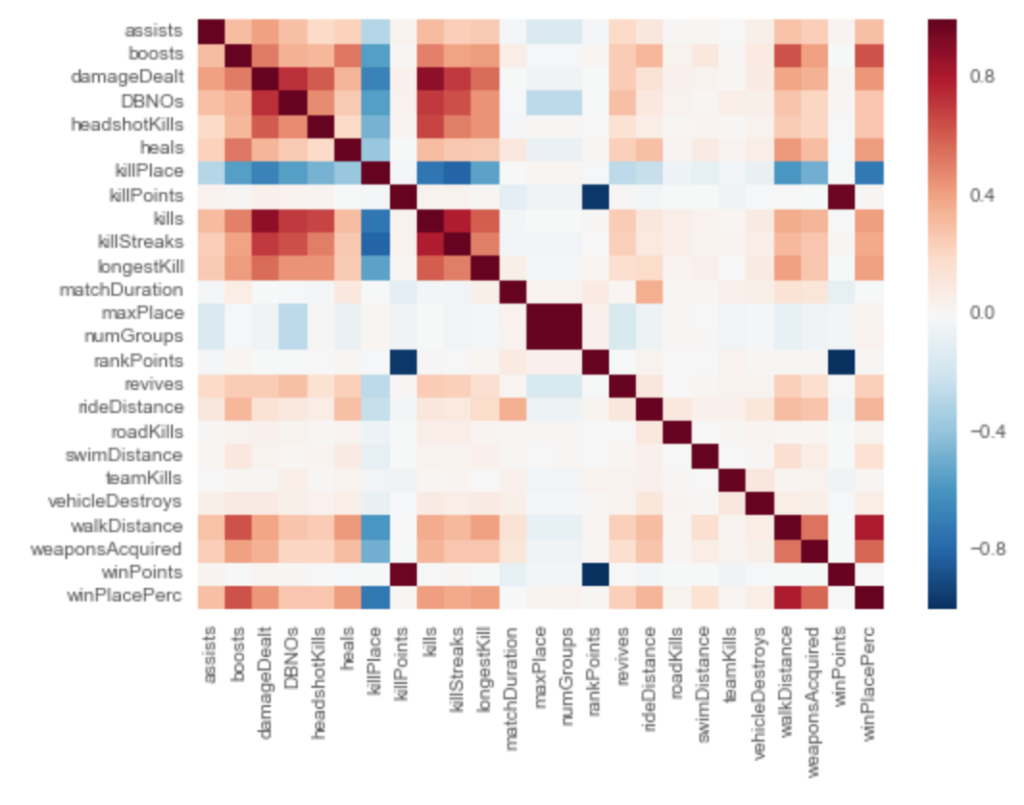
最終順位に対して、単純に相関が高そうな「kills(キル数)」よりも、「walkDistance(歩行距離)」、「boosts(ブーストアイテム使用数)」、「weaponAcquired(武器入手数)」の方が相関が高いのは、ゲーマー心をくすぐりますね。
| (3) 本コンペの特徴と取り組み
本コンペでは、下記2点が重要であったと思います。
・ドメイン知識からの特徴量生成
・順位予測としての後処理
・ドメイン知識からの特徴量生成
ドメイン知識から、下記のように大きな分類を整理していきました。
b) 時間系。時間あたりの行動。総試合時間に対する行動割合。
c) kill割合・kill頻度。1killに対して、何をしたか。
d) 仲間のサポート系。どれだけアシスト、カバーができていたか。
e) テクニック系。
f) プレイスピード、総アクティビティ系
g) 順位系。該当試合における全プレイヤーの中での
h) グループごとの統計量(最大、最小、平均etc)
a)〜f)は各自のプレイに関するもの、g)はそのログに関する各マッチにおける順位、h)は マッチにおけるグループごとの統計量となります。この中でも、特に最終順位予測に効果的だったのは、g)順位系と、h)グループごとの統計量となります。最終予測が他のプレイヤーとの相対的な順位なためh)の順位はわかりやすいと思います。pythonでは下記のようにすることで任意のグループにおける、あるカラムの順位を算出できます。
|
1 |
data[c + "_rank"] = data.groupby("matchId")[[c]].rank(pct=True) |
もっとも私のモデルで重要度が高かったのは「潜伏時間」です。これは「プレイ中の移動していない時間」の指標で周囲の状況把握のための上位プレイヤーと下位プレイヤーを分ける指標なのではと思い、様々な計算をしました。最終的に採用した計算式は下記となります。
all_data[‘_hideDuration’] =
all_data[‘matchDuration’] – (round(all_data[‘walkDistance’] / 6) + round(all_data[‘rideDistance’] / 277) + all_data[‘swimDistance’] / 1)
各歩行、乗り物、水泳、移動距離を平均的な移動速度で割って移動時間を算出し、それらの合計を試合時間全体から引くことで、逆に「移動していない時間」を割り出しております。
※6m/sは歩行の平均移動速度、277m/sは乗り物の平均移動速度、1m/sは水泳の平均移動速度(ファンサイトその他からの概算です。)
※matchDurationは試合の長さであり全プレイヤーで共通です(プレイヤーごとのmatchDurationとするとリークとなるため提供されていません)
※もちろん、試合時間は前述の通りあくまでプレイヤーごとに共通の試合時間となります。そのため、本来はプレイヤーごとの生存時間から総移動時間を引きたかったのですが妥協案として上記の式としております。
その他、e) テクニック系は、たとえば、killをただとるだけではなくヘッドショットで最大ダメージを与えることができたか、あるいは連killをとれたかなどの指標となります。kill合計は重要な指標でありながら、できるだけスマートなkillをとれるユーザの方が、上位プレイヤーである可能性は高まります。
最終的に、下記の特徴量を採用しました。 all_data[‘_headshotKillRate’] = all_data[‘headshotKills’] / all_data[‘kills’]
all_data[‘_killStreakrate’] = all_data[‘killStreaks’]/all_data[‘kills’]
その他、scikit learnのPolynomialFeaturesを用いて変数の掛け合わせを自動生成することもしました。
・順位予測としての後処理
今回の目的変数は各マッチごとの最終順位%(最高順位が1、最低順位が0)、評価指標はmaeです。そのためまずは各ログから最終順位%を回帰で予測するということがベーシックなアプローチとなります。ただしグループごとの順位を計算するために予測値からの後処理が考えられます。もっとも単純なアプローチは予測値を0,1の範囲にclipすることです。それ以上により有効な方法については上位ソリューションの章で後述します。
| (4) 余談1:パイプライン構築について
本コンペに限りませんが、コンペに取り組むにあたり、ベースラインコードを構築するだけではなくパイプラインを整備することは非常に重要です。実験ごとのパラメータ/特徴の追加/変更とその予測結果精度をどのように可視化/保存するかといった開発・実験管理の整備です。実は本コンペに取り組んだ当時は自前のコードでそれらを行っていたのですが、近年WandBを用いることでパイプラインの構築を非常にスマートに行うことができるため、本章ではWandBを用いた方法について紹介します。
WandBとは、正式には「Weights and Biases (WandB)」であり機械学習のための実験管理プラットフォームです。モデルの学習中の様々な実行環境やパラメータ、結果を保存・可視化することができます。実験の終了をメールやslackなどで通知することも可能です。個人で使用する場合、基本的には無料で使えます。
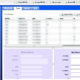
下記のように実験(実行環境やパラメータ、特徴量etc)ごとの結果(epochごとのlossの推移など)を比較することが簡単に可能です。
※前述の通り本コンペ参加中はまだWandBを使用していなかったため、下記はコンペ終了後の復習時に実行したときのキャプチャ
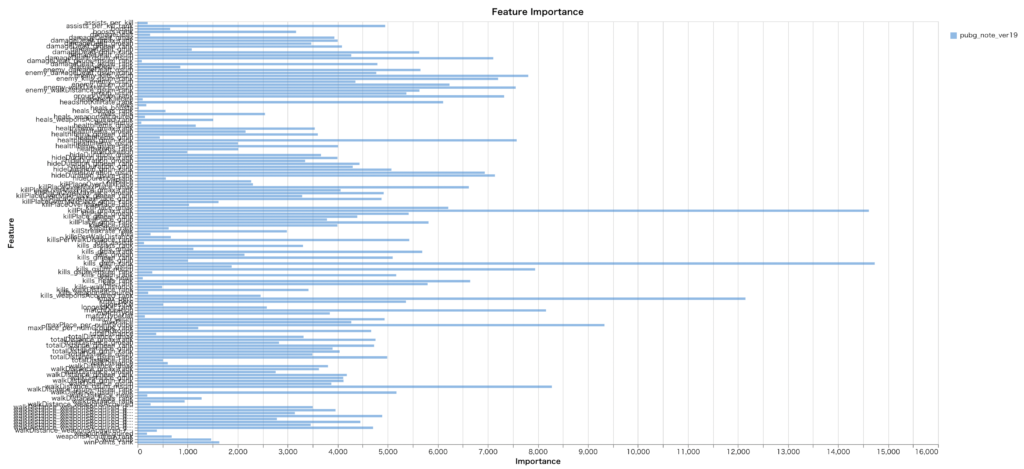
また特徴量ごとの重要度についても下記のように可視化で確認できる他テーブル形式で簡単に記録し、WandB上で確認することができます。
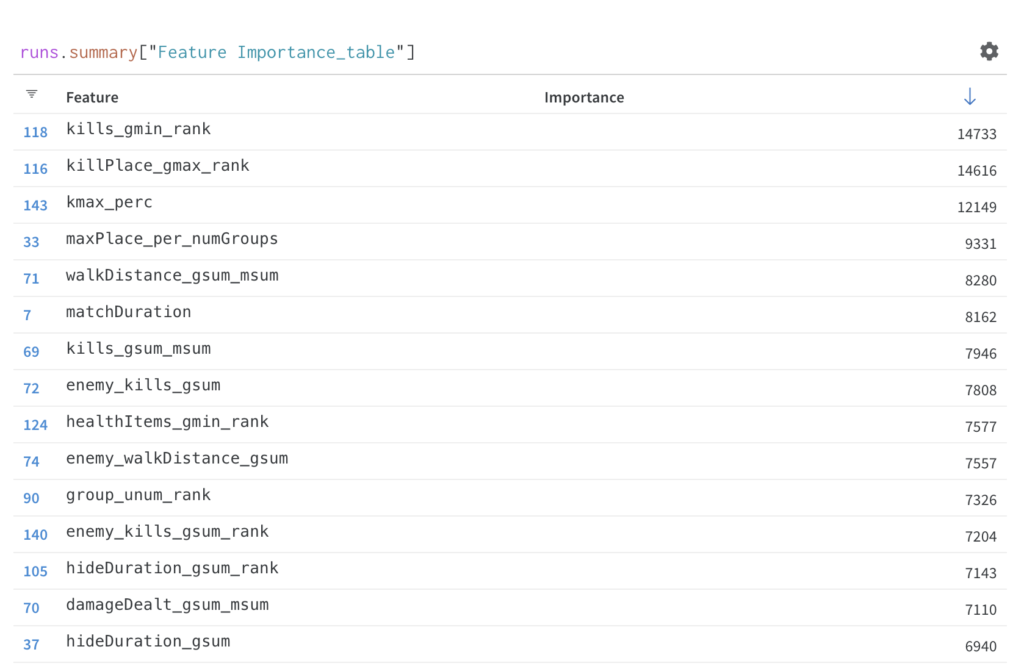
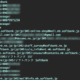
導入する手順は非常に簡単でWandBでアカウントを作成し、pip install wandbでwandbのパッケージをインストール後、下記のコードをプログラムの冒頭に挿入します。
|
1 2 3 |
import wandb wandb.login() wandb.init(project="(任意のプロジェクト名)", name="(任意の実験名)") |
またWandBではlightGBMの実行記録用の様々な機能がサポートされており、それを使用するためには下記も記載しておきます。
|
1 |
from wandb.integration.lightgbm import wandb_callback, log_summary |
あとは実験ごとに保存しておきたい値をwandb.config()で記録していくのですが、lightGBMの場合は、lgb.trainのcallbackでwandbを呼び出すことで、学習実行中の経過を保存することができます。
|
1 2 3 4 5 |
model_lgb = lgb.train( *** callbacks=[wandb_callback()] *** ) |
学習終了後のlightGBMモデルの結果(特徴量の重要度)については下記で保存可能です。
|
1 |
log_summary(model_lgb, save_model_checkpoint=False) |
最後に下記を記述することで実験の記録が完了します。
|
1 |
wandb.finish() |
| (5) 余談2:EDA/チーターと回線落ちについて
ドメイン知識は特徴量生成のほかEDA中の異常値の判断としても求められます(最終的にパイプラインに組み込むかはともかく)。最終的にそこまで精度にインパクトのなかった余談ですが例えば「チーター(Cheater)」と「回線落ち(Zombi)」の存在というトピックがあります。
「チーター(Cheater)」とは、不正なコードを用いて、改造データでプレイするユーザのことで、たとえば、「一歩も動かずに敵をキル」するような改造や、「異様な速さで移動する」、「攻撃の命中率が異様に高い」改造などが、あげられます。実際、今回のデータでも、「攻撃のヘッドショット命中率(頭を狙うとダメージが大きい)が(常識的な上限である)80%よりも高い」ユーザデータが見られます。
一方で、「回線落ち(Zombi)」ですが、試合にマッチングしたものの、プレイ開始後に、回線が途切れ、ゲーム内で全く動かなくなるユーザとなります。※スプラトゥーン2などでは、回線落ちユーザはゲームから消失しますがPUBGでは、通称ゾンビと呼ばれるように、回線落ちしても動かくなるだけで残ります。今回のデータ中にも、「一歩も動かず、キルもせず、武器も入手していない」ユーザデータが見られます。
チーター、回線落ち、それぞれ、今回のデータセット中の数、およびドン勝(順位1位。最終的な生き残り)率への影響は下記となりました。
| タイプ | train_data内 該当数 | test_data内 該当数 | ドン勝率 |
| 全体 | 4,446,966 | 1,934,174 | 47.28% |
| チーター | 1,630 | 332 | 49.68% |
| 回線落ち | 78,384 | 34,120 | 2.5% |
チーターは規模が小さい上に、勝率がそこまで劇的によくもないという結果ですが、回線落ちは規模がそれなりに存在する上に勝率に影響する(回線落ちでドン勝、上位になることはない)結果となりました。これらの存在をいかに扱うか(あるいは気にしないのか)が、ひとつの判断となります。私はチーターの存在は無視し回線落ちについては特徴量としてフラグを立てる、という処理をしました。
しかし、当然、上記のような存在は、ゲーマー以外は馴染みのない異常値となり、実際、KaggleのDiscussionボードなどでは、ゲーマー・非ゲーマー間のデータサイエンティストのやりとりが散見されました。
[Kaggle内のデータサイエンティストたちのやりとり ※意訳]
非ゲーマー「たとえば非常に高い命中率のプレイヤーがいるのは、どのように考えたらよいのでしょう」
ゲーマー「それはね、チーターだよ」
非ゲーマー「一歩も動かず、キルもしていないユーザが途中まで生き残っているのはどのように考えたらよいのでしょう」
ゲーマー「それはね、回線落ちだよ」
非ゲーマー「Ummm….私は、非常に混乱してきました。」
正直、少し同情しました。
| (6) 結果と上位ソリューション
結果は331位/1530チームとなり、良い成績は残せませんでした。
公開されている上位ソリューションを確認しますと、特徴量生成は前述のアプローチが基本となり、そこまで大きな差は出ていませんでした。大きな差が出たのは順位予測をするという上での後処理であったように思います。特に1位ソリューションは「killPlace(マッチ中のkillの順位)」が目的変数である「winPlacePerc」のリークを含むことをうまく利用していました。実はkillPlaceの値は同じkill数であった場合にはwinPlacePerc順でソートされていることがディスカッションで報告されていました。多くの人がkillPlace自体が重要な特徴量であるためkillPlace関連の様々な特徴量を追加するということ以上のことはできなかったなか、1位チームは最終的なプレイヤーの並び替えの後処理のための情報として活用していました。
他のコンペでも痛感しておりますが公開されているディスカッションでの知見のうち精度に直結するようなアイデアはもちろん、多くの人にとって(興味深いものの)アプローチには採用しづらいような情報でさえも、うまく最終的な処理として活用する発想と実装力を高めていかなければならないと思った次第です。
| (7) おわりに
私はそもそもが根っからのゲーマーであるにとどまらずゲーム実況配信をしている(いた)ほか、ITmediaにスプラトゥーン2のデータ解析記事を寄稿したりしておりまして、本コンペは非常に高く楽しく取り込むことができました。コンペではできるだけゲーマーとしての実感を活かせるよう、(そして、分析結果をPUBGのプレイにフィードバックできるよう)EDAよおび特徴量の生成に力を入れました。結果は振るわなかったですが、ぜひまた本コンペのようなゲームプレイログを題材にしたコンペが開催されることを心待ちにしております。
次回のKaggleこそ、「勝った!勝った!夕飯はドン勝だ!!」
関連記事:





人気記事: