Article
今回は体組成データを取得する手順を見ていきます。
現在、市販で様々な体組成計が販売されているほか、
ヘルスデータ取得用のウェアラブルデバイスやアプリなども充実していることから、
多様な手段で体組成データを取得することができます。
その中でも今回はタニタの体組成計で計測したデータを
APIのOAuth認証でRuby経由で取得する手順を見ていきます。
ちなみにタニタの体組成計は下記のようなものです。

OAuth認証は、API連携で良く使われる手段で、
一般的なOAuth認証と同様、tanita APIも下記手順でデータにアクセス可能です。
(1) APIを用いたアプリ/サービス開発のためのClient_ID、Client_Secretをサービス提供者(タニタ)から取得する
(2) 上記サービスのClient_IDを用いて(ブラウザ経由で)ユーザにデータへのアクセス許可を求め、access_codeを取得する。
※あるアプリが、API経由でユーザ情報を取得していいか、ユーザごとに確認。
(3) client_ID、client_secret、access_codeを用いて、リクエストトークンを取得する。
(4) 取得したリクエストトークンを用いてAPI経由で情報を取得する。
まずは、タニタの体組成API(Health Planet API)を用いたアプリ開発のための
Client_ID、Client_Secretを取得しておきます。
タニタのAPIは、「Health Planet API」で管理されておりますので、
まずはHealth Planetの会員登録をしておきます。(画面左上から登録)
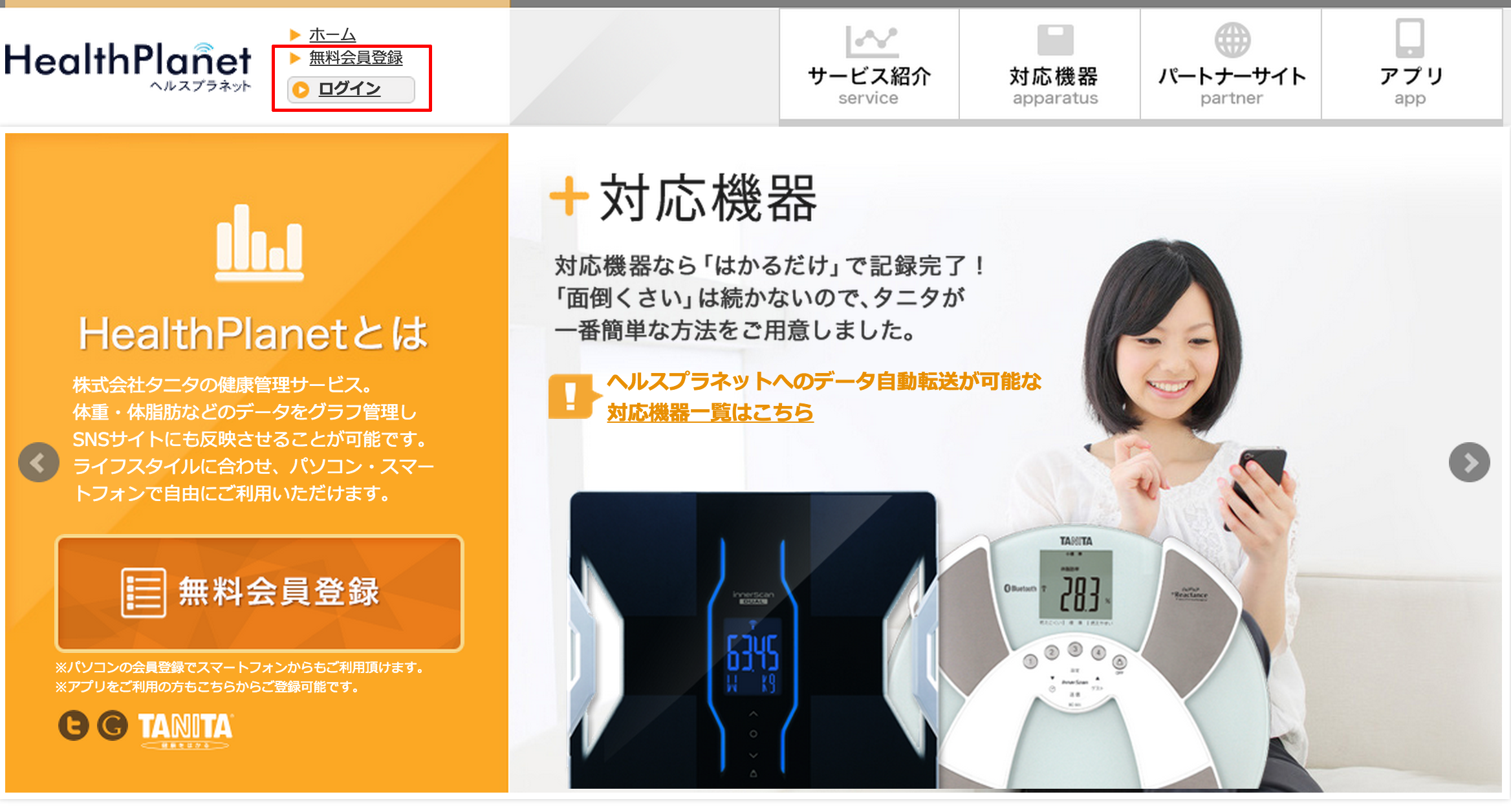
ログイン後、右上のメニューから「登録情報の確認・変更」を押して
スクロールしていくと、「アプリ連携」の項目があります。
その中の、「アプリケーション開発者の方はこちら」を押して、
「新規登録」すると、Client_ID、Client_Secretを取得する事ができます。
では、次にOAuth認証の処理をRubyで実装していきます。
なおRubyにはoauth/oauth2などのパッケージがあるのですが、
今回はmechanizeでの実装をしてみます。
まず、必要なパッケージを呼び出します。
|
1 2 3 4 |
require 'mechanize' require 'nokogiri' require 'json' require 'csv' |
次に、「Client_IDを用いて(ブラウザ経由で)ユーザに
データへのアクセス許可を求め、access_codeを取得する。」手順を実装します。
タニタAPI(Health Planet API)は、下記のブラウザで動作するようなので、
以下いずれかのagentに設定します。
Internet Explorer 8及び9、Mozilla Firefox 6、Google Chorme 13、Safari 5
|
1 2 3 |
agent = Mechanize.new agent.user_agent_alias = 'Windows IE 9' url = "https://www.healthplanet.jp/oauth/auth?client_id=#{CLIENT_ID}&redirect_uri=#{REDIRECT_URI}&scope=innerscan&response_type=code" |
まずは、HealthPlanetにログインし、次に、
API経由での認証許可のためのボタンクリックをします。
|
1 2 3 4 5 6 7 8 9 10 11 |
page = agent.get(url) login_form = page.forms_with(:name => 'login.LoginForm').first login_form.fields_with(:name => 'loginId').first.value = USER_ID login_form.fields_with(:name => 'passwd').first.value = USER_PASS page2 = login_form.click_button login_form2 = page2.forms_with(:name => 'common.SiteInfoBaseForm').first login_form2.fields_with(:name => 'approval').first.value = 'true' page3 = login_form2.click_button AUTH_CODE = page3.uri.query[5,page3.uri.query.length-5] |
以上でアクセスコードが得られますので、
client_id、client_secretとともに、
アクセストークンを取得します。
返り値はJSONで得られるので、アクセスコードのみをparseしておきます。
|
1 2 3 4 5 6 7 8 9 |
page4 = agent.post('https://www.healthplanet.jp/oauth/token', { "client_id" => CLIENT_ID, "client_secret" => CLIENT_SECRET, "redirect_uri" => REDIRECT_URI, "code" => AUTH_CODE, "grant_type" => "authorization_code" }) access_array = JSON.parse(page4.body) |
ここまでで準備が完了しましたので、あとは、用途に応じて必要な期間の値を
適切なフォーマットでcsvに書き出すかサービスに値を渡すとよいでしょう。
ちなみにHealth Planet APIでは下記数値が集計できます。
※値は3ヶ月ごとの範囲のみで指定できますので、もっと長い期間のデータが必要な場合は、
適宜ループ処理をかませてください。
※値の取得は1時間60回までの制限がありますのでご注意ください。
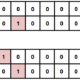
| tag | 値 |
| 6021 | 体重 (kg) |
| 6022 | 体脂肪率 (%) |
| 6023 | 筋肉量 (kg) |
| 6024 | 筋肉スコア |
| 6025 | 内臓脂肪レベル2(小数点有り、手入力含まず) |
| 6026 | 内臓脂肪レベル(小数点無し、手入力含む) |
| 6027 | 基礎代謝量 (kcal) |
| 6028 | 体内年齢 (才) |
| 6029 | 推定骨量 (kg) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ACCESS_TOKEN = access_array["access_token"] DATE_TYPE = 0 TAG = 6021,6022,6023,6026,6027,6028 TAG_PARAMS = 6 FROM_DATE0 = "20140301000000" TO_DATE0 = "20140531235900" CSV.open('health.csv','wb',:encoding => 'SJIS') do |csv| url2 = "https://www.healthplanet.jp/status/innerscan.xml?access_token=#{ACCESS_TOKEN}&date=#{DATE_TYPE}&tag=#{TAG}&from=#{FROM_DATE0}&to=#{TO_DATE0}" page5 = agent.post(url2) doc = Nokogiri::HTML.parse(page5.body.toutf8) datas = doc.xpath("//data") dates = doc.xpath("//date") keydata = doc.xpath("//keydata") tags = doc.xpath("//tag") for num in 0..datas.length.to_i csv << [dates[num],keydata[num],tags[num]] end end end |
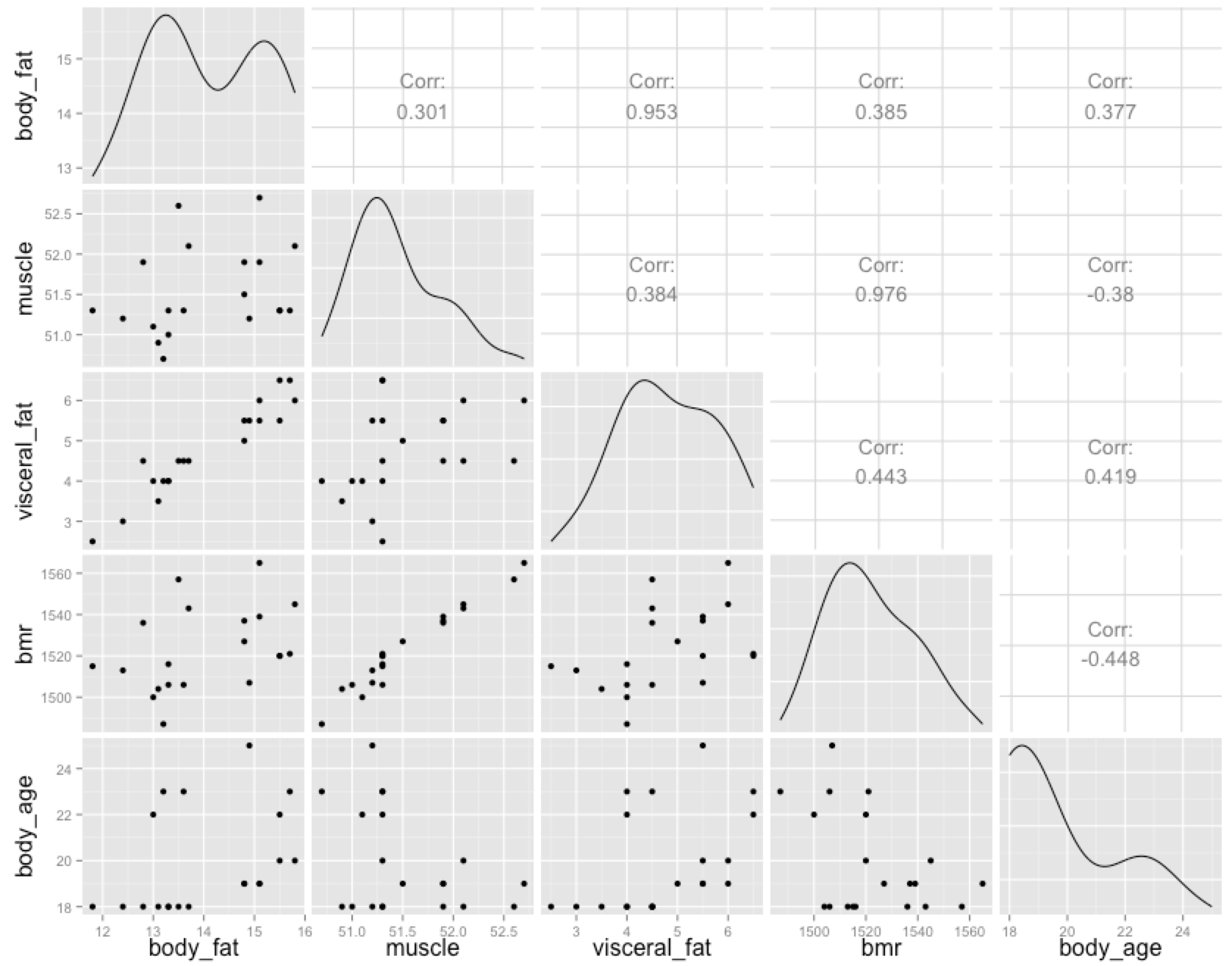
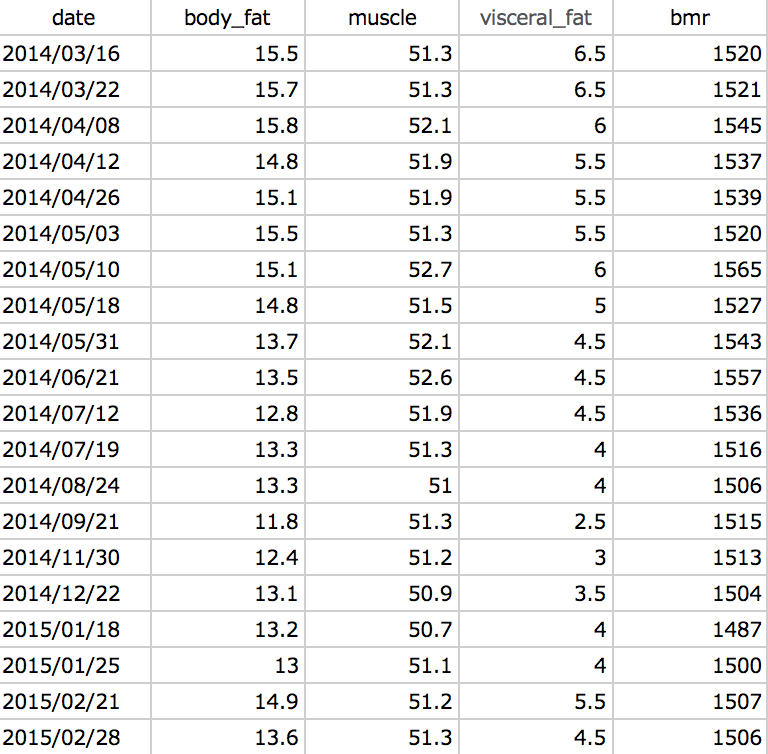
たとえば、上記処理で得られたcsvを整形し、
得られた結果をRに入れてプロットしたものが以下となります。

以上、今回は、体組成データの取得の仕方を見ていきました。
関連記事:



人気記事: