Article
サッカーとデータサイエンス
みなさんは好きなスポーツ、ご贔屓のスポーツチームはありますでしょうか。
私はサッカーが好きで、特に横浜F・マリノスが大好きです。
マリノスのホームスタジアムである日産スタジアムは何度訪れたかわかりません。
今年はJリーグもコロナの影響で無観客試合があったものの、夏頃から人数制限つきで観戦できるようになりましたので、
秋は久々に足繁く日産スタジアムに通う日々を過ごしておりました。



日本代表戦も観に行きます。
なんならロシアワールドカップは現地で観戦しましてテレビにも見切れました。良い思い出です。
そんな私の普段の仕事はデータ分析でして、
サッカーのデータ分析記事の寄稿もしばしば行っております。
「2016年のJ1全試合を機械学習で分析し2017年の展望を予測する」(football-lab)
さて、そんなサッカーとデータサイエンス好きな私にとって、
非常に面白そうなデータ分析コンペが先日Kaggleで開催されました。
今回は、Kaggle “Google Research Football with Manchester City F.C.”コンペ(通称footballコンペ)で
1141チーム中97位(ブロンズメダル)となりましたので、自分の取り組みについて振り返ります。
※あくまでブロンズメダルですので、これが正解という解法公開ではない点、ご留意くださいませ。
個人的な反省と振り返りです。上位解放については後半でレビューいたします。
footballコンペの概要
本コンペはイングランドの名門サッカークラブであるマンチェスター・シティFCとGoogle Researchの共同開催による、
“AI football”コンペとなります。

Kaggleとしては以前記事に書いたHaliteコンペに続き、2つ目のメダル授与対象のSimulationコンペとなります。
Simulationコンペとは、通常の正解データがある予測コンペとは異なり、
ゲームなどを題材に、ユーザが作成したプログラムの”agent”同士を対戦させることで順位を競うコンペとなります。
※ユーザがインタラクティブに操作するのではなく、作成したプログラム(agent)でゲームを実行する
ルールは基本的に通常のサッカーと同じです。ファールもオフサイドもイエロー/レッドカードも判定されます。
そして、各プレイヤーの疲れも考慮されます。
また体の向きもアクションに重要であり、移動速度は慣性を持ちます。(急な逆方向への切り返しはできない。)
なお、プログラムで操作できるのは同時に1人の選手のみとなります。その他の選手は自動で動きます。
操作対象の選手はシステムで自動的に判断されますが、通常ボールに最も近い選手であることが多いです。
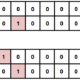
操作対象に対して下記の18パターンの命令を行うことができます。
・00 : idle(何もしない)
・01 : left(左へ移動)
・02 : top_left(左上へ移動)
・03 : top(上へ移動)
・04 : top_right(右上へ移動)
・05 : right(右へ移動)
・06 : bottom_right(右下へ移動)
・07 : bottom(下へ移動)
・08 : bottom_left(左下へ移動)
・09 : long_pass(ロングパス)
・10 : high_pass(浮き玉パス)
・11 : short_pass(ショートパス)
・12 : shot(クリア・シュート)
・13 : sprint(ダッシュ)
・14 : release_direction(移動方向キャンセル)
・15 : release_sprint(ダッシュキャンセル)
・16 : sliding(スライディング)
・17 : dribble(ドリブル)
・18 : release_dribble(ドリブルキャンセル)
つまり、敵味方およびボールの様々なポジションごとに
上記18パターンのどのアクションをすることが効果的かを分析・実装することを競うコンペとなります。
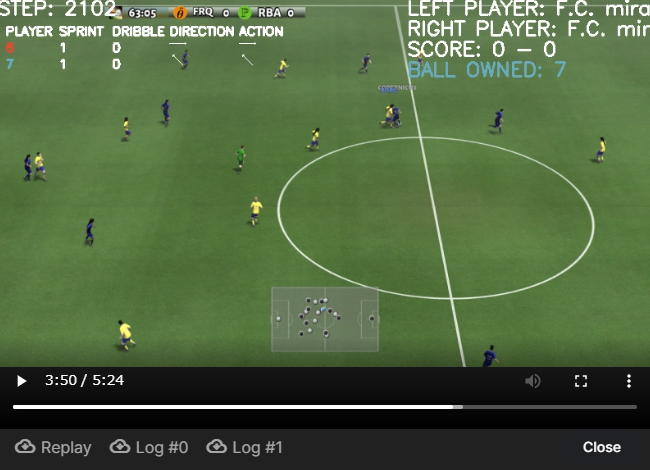
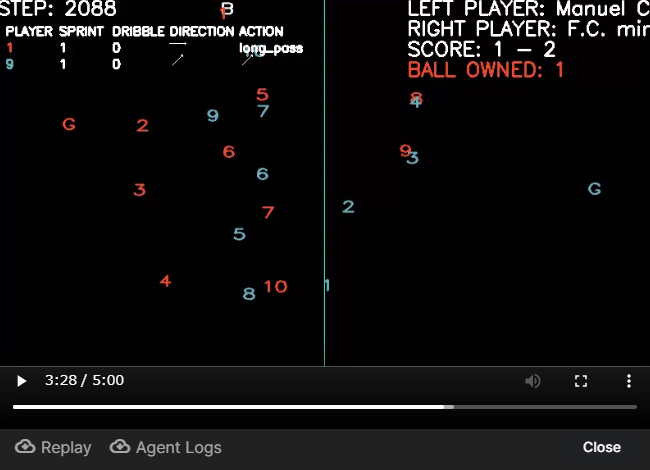
他のユーザagentとの対戦過程は、下記のような2Dあるいは3Dアニメーションにて確認できます。
※コンペ当初は対戦相手との結果は全て3Dでしたがマッチング回数を増やすために途中から2D/3Dを織り交ぜたものになりました。
上記とともに各試合ごとにJSONデータでお互いのアクション履歴などをダウンロードすることができます。
前回のsimulationコンペでは1位のチーム筆頭にルールベースが多かったですが、
今回のfootballコンペでは、下記3種類の方針がメダル圏にそれぞれ見られました。
・ルールベース:if文などで条件を記述して組み合わせて制御
・機械学習ベース:過去の対戦ログなどから、各状態ごとによりよいプレイヤーの行動などを学習して予測するモデルを作成して制御(模倣学習)
・強化学習ベース:自己対戦を繰り返して報酬によってよりよい行動をとるモデルを作成して制御
私は、「ルールベース+機械学習ベース」で実装しました。
強化学習を用いなかったのは多分にスキル不足によるところがあります。
「ルールベース+機械学習ベース」で行なった具体的な詳細を次から述べていきます。
対戦ログのデータ分析(EDA)
ルールベース、機械学習ベースどちらにも必要な作業として、
トッププレイヤーの対戦ログをJSON形式で収集し、様々な切り口で分析しました。
シュート位置
まずはじめに一番気になる「シュート位置」を分析しました。
下記は様々な試合での、あるトッププレイヤーのシュート位置です。
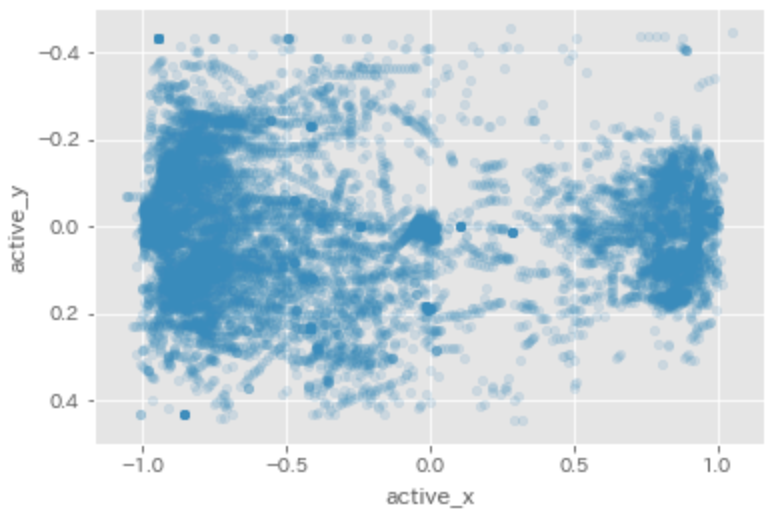
左側が自陣、右側が敵陣なのですが、ぱっと見たときに、まず自陣側でもシュートアクションをしていることがわかります。
シュートアクションは、自分の向きに関わらず、敵ゴールに向かってボールを放つため、クリアとして有効であり、
自陣深い位置であれば、パスでつなぐより、体勢や敵味方のポジションによってはシュートアクションによるクリアがよく選択されているようです。
次に、シュート位置ごとのゴールが決まる確率を分析してみます。
シュート位置をグリッドで区切り、グリッドごとのシュート回数におけるシュート決定率を求めます。
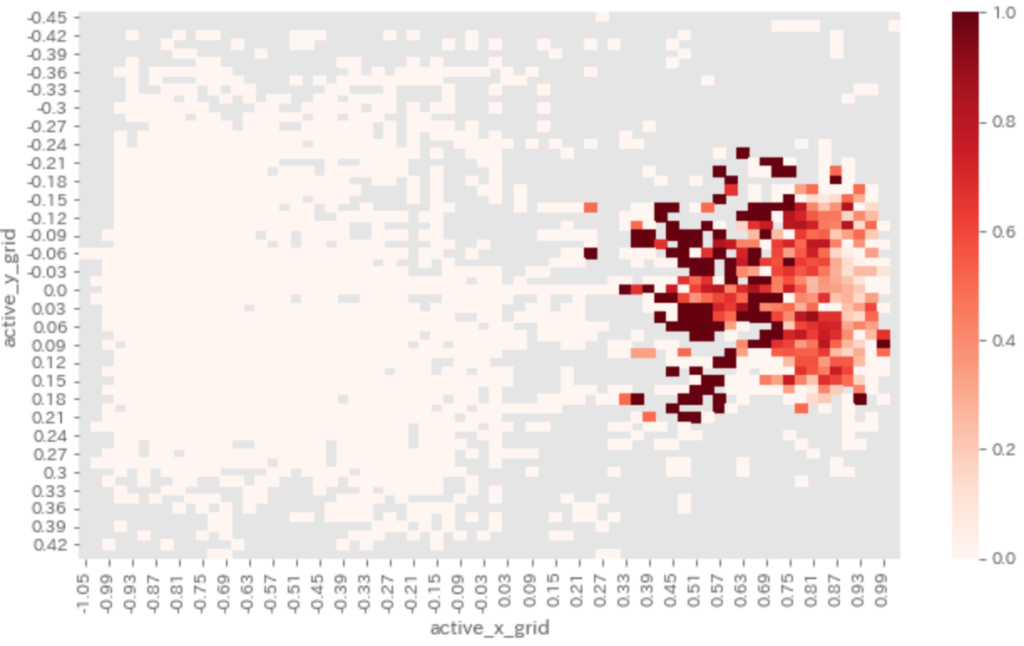
濃い赤であるほど決定率が高いことを意味するのですが、
敵ゴール(敵ゴールキーパー)に近いほどゴールが決まるというわけではなく、
適切な距離感、そして真正面より少しだけずれた角度、あるいは斜めからの切り込みが有効であるようです。
ゴール近くであっても角度のないところからのシュートは決定率が低いようです。
ここら辺は現実のサッカーとも同じで納得感がある結果となりました。
上記の結果をもう少し細かく分析していきます。
まずはゴールが決まったシュートにおける、自分と敵GKとの距離をみてみます。
縦軸をゴールが決まったシュート本数、横軸を自分と敵GKとの距離とした図をプロットします。
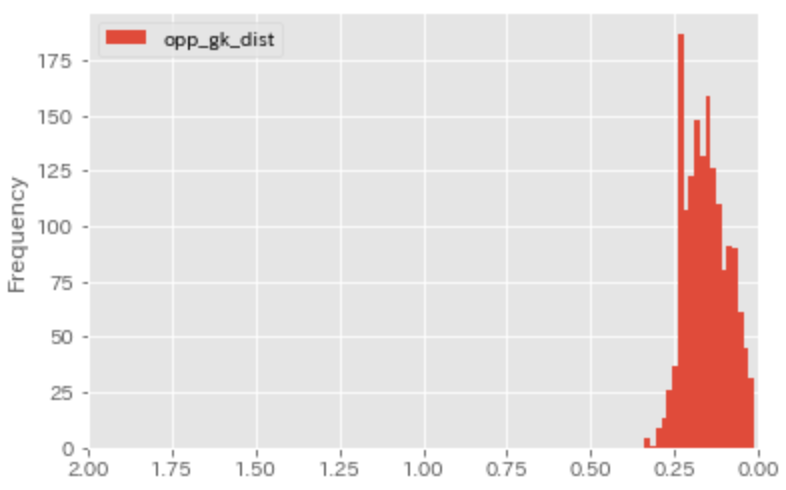
ゴールが決まったシュートは25m前後がひとつの目安のようです。
ただ、敵GKとの距離やゴールとの角度といったポジションだけでゴールの決定率が決まるわけではありません。
下記はゴールが決まったシュートを打ったときの、自分と敵ゴールとの角度差となります。
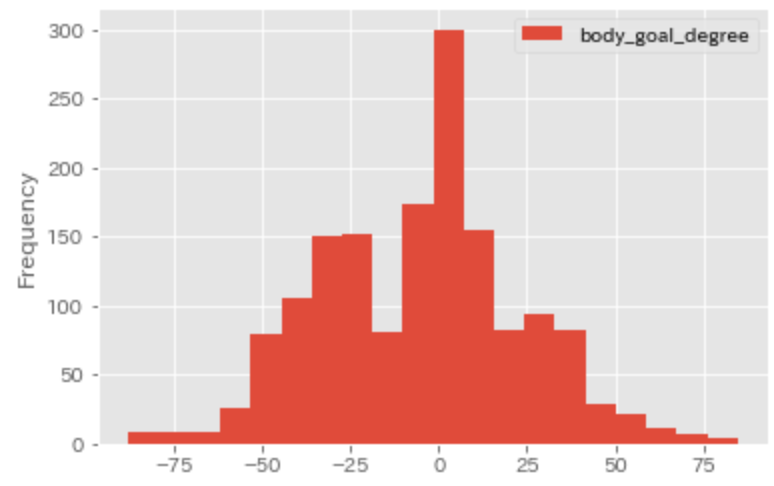
その他、敵位置や味方位置など様々なシュートシチュエーションを分析しました。
スライディング位置
次にディフェンスの観点から分析していきます。
実行可能なアクションの中に「スライディング」があるのですが、
これをどのように活用するのか、をコンペ序盤にかなり悩みました。
というのも、うまく使用しないとかなり高確率でファールになるのです。
逆に言うと「ファールになっても相手の攻撃を止めたい」というシーンは往往にしてありまして、
相手に裏抜けされたときなど、ファールすることでリスタートにして、
ディフェンスポジションを整えることができるメリットがあります。
下記はトッププレイヤーにおけるスライディング位置となります。
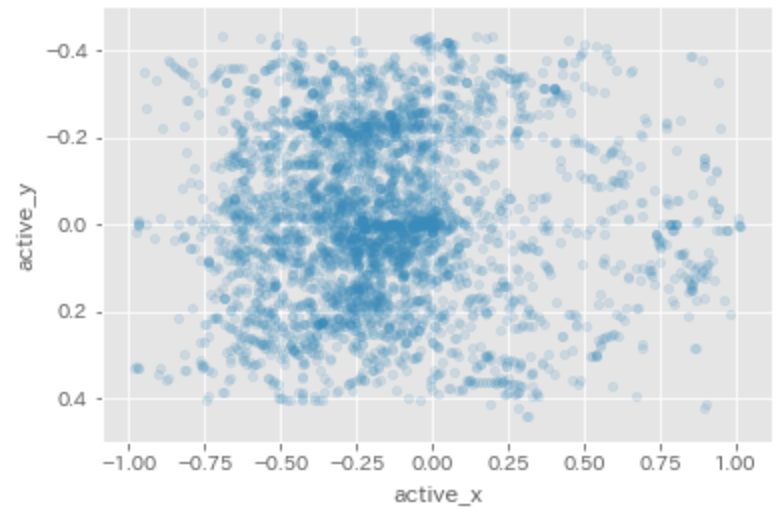
左が自陣、右が敵陣なのですが、
ハーフラインを超えたあたりでスライディングをすることが多いようです。
ただ、自陣のゴール付近ですとPKを与えるリスクが高いことからx軸-0.75以下でy軸-0.2〜0.2の範囲内では、
スライディング頻度が減ることがわかります。
また、敵陣の前線でもしばしばスライディングしているようです。前線からの守備でボール奪取できた場合、
非常に大きなチャンスになるので有効活用していきたいところです。
リスタート時のアクション
その他、スローイン、フリーキック、コーナーキックなどリスタートごとのアクションについても分析していきました。
リスタート時はシチュエーションが限られるため、ルールベースでも作り込みできますし、
機械学習するにしても学習しやすいように思います。
トッププレイヤーのスローイン時における各アクション頻度をプロットしてみます。
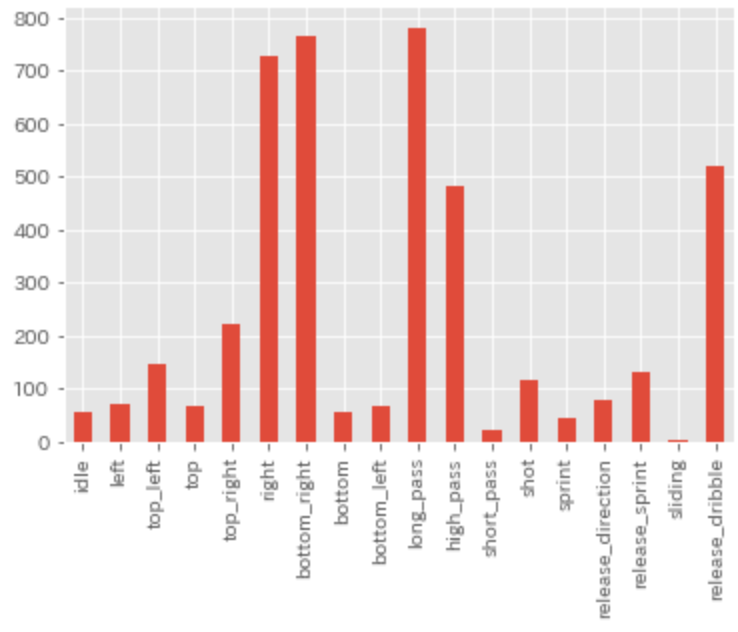
右方向を向いてhigh_passをする、というアクションが目立ちます。
ここで、スローインの位置ごとに集計してみます。
まずは自陣深いエリアでのスローイン時のアクションです。
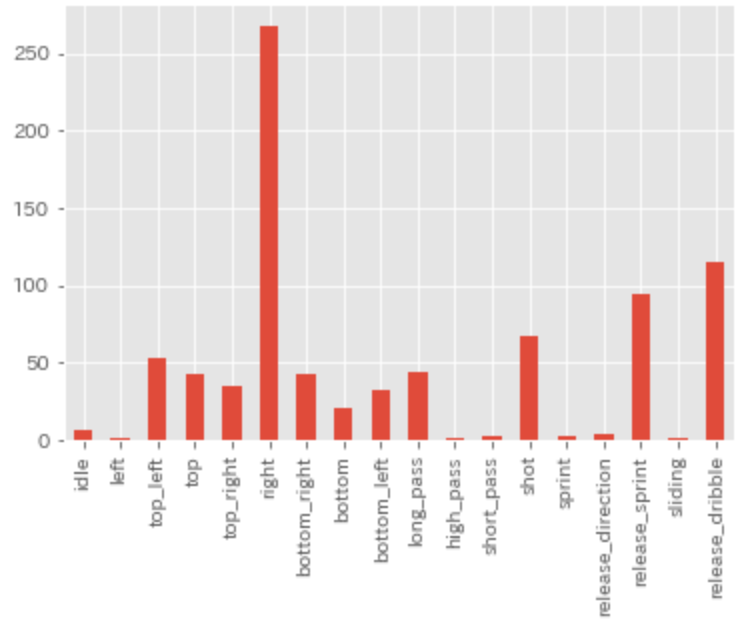
top_left/bottom_leftといった斜め右ではなく、右(真横)を向いた上で、
shotつまりクリア、というアクションが多いようです。
続いて、敵陣深いエリアでのスローイン時のアクションをプロットしてみます。
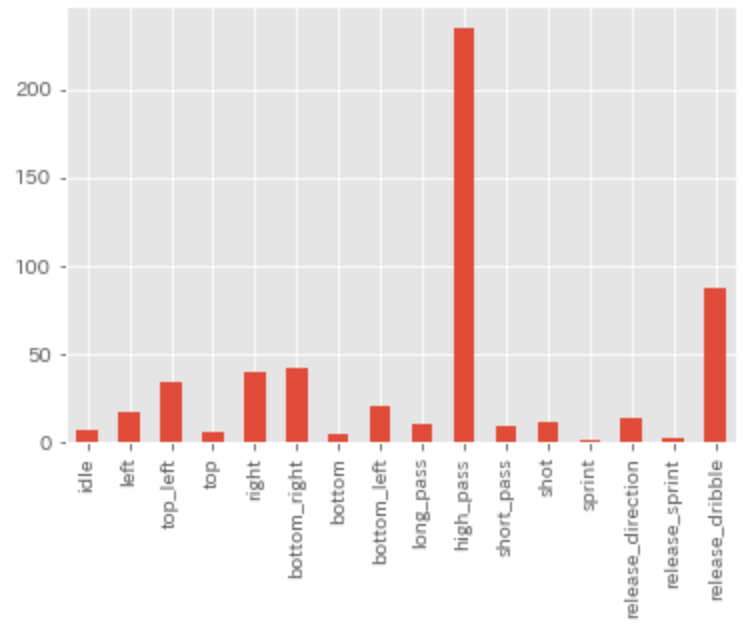
敵陣深いエリアでは横を向くアクションはなく、
high_passをしてゴール前にあげる、というアクションが目立ちます。
このように各シチュエーションにおいてポジションが非常に重要となるため、
フィールドをいくつかに分割して、それぞれにアクションを分析していきました。
ルールベースでは、ロジック自体が正しくても閾値が違うと大きく結果が異なることがあり、
以上のような集計はルールベースにおける閾値設定において特に重要でした。
また、機械学習ベースにおいても、データ分析およびルールベースでの構築を通して、
新しい特徴量を作成することに役立ちました。
最終的には、ルールベースである程度作り込んだ上で、
機械学習ベースで作成した各stepごとのモデルの予測が0.6以上の確信度出会った場合は、
機械学習ベースに従う、という実装にしました。
機械学習における特徴量
機械学習ベースのモデルにおいては大きく下記5種類の特徴量を作成しました。
現在位置
ボールおよび、敵味方11人づつの現在位置の情報です。
未来位置
ボールおよび、敵味方11人づつの現在の移動速度・加速度から計算した未来位置の情報です。
未来位置は、1/3/5/7/10step後を計算しました。(のちに精査)
コントロールプレイヤーを中心とした相対位置
コントロールプレイヤーを原点とした極座標での相対位置(原点からの距離、角度)となります。
ゴールポテンシャル
自分とゴールとの距離、自分と敵ゴールキーパーとの距離、
自分の体の向き(および敵ゴールとの角度差)、
前述のポジションごとのゴール確率、などの情報となります。
シチュエーション
どちらのチームがボールを持っているか、フリーのボールなのか、
どちらかのチームのリスタート時なのかというシチュエーションに関する情報です。
特にログを見ていると、意外にどちらのチームのボールでもない、
フリーのボールと判定される瞬間が多くあり、
ロングパスをあげた直後など自分のボールではないものの、自分の攻めのターンとも考えられ、
ダイレクトプレーに関するシチュエーションは重要でした。
※自分がボールを保持していたらシュート、というアクションでは遅いことが多く、
自分がボールを保持していないがボールが自分に向かってきているなら
シュートアクションをとるなど。
上記のシフト特徴量などを加え、機械学習ベースの予測モデルを作成いたしました。
モデルを作成後は、ローカルで自分のこれまでのモデルと様々なシチュエーション
(今回のコンペ用プラットフォームでは通常の11vs11のほか、3vs1など様々なモードが用意されていました)で対戦させて、
結果を確認しました。
(“Local Agent Evaluation Framework”というNotebookが非常に参考になりました。)
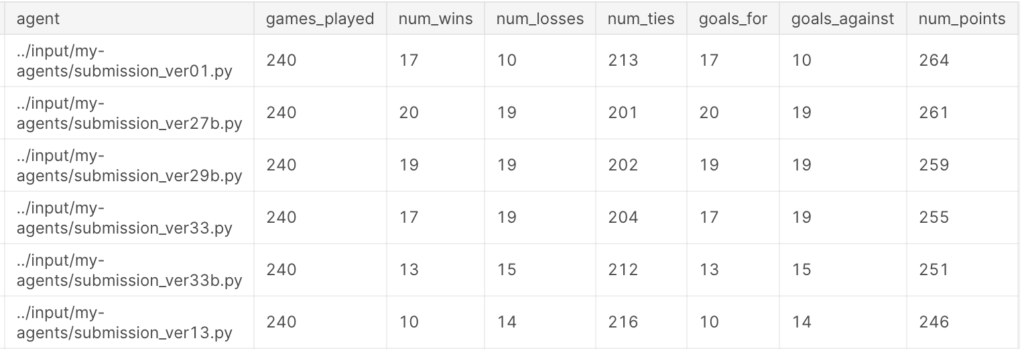
以上から、ルールベースのベースラインと合わせて最終アクションを決定するagentを作成し、
1138チーム中97位(ブロンズメダル入賞)となりました。
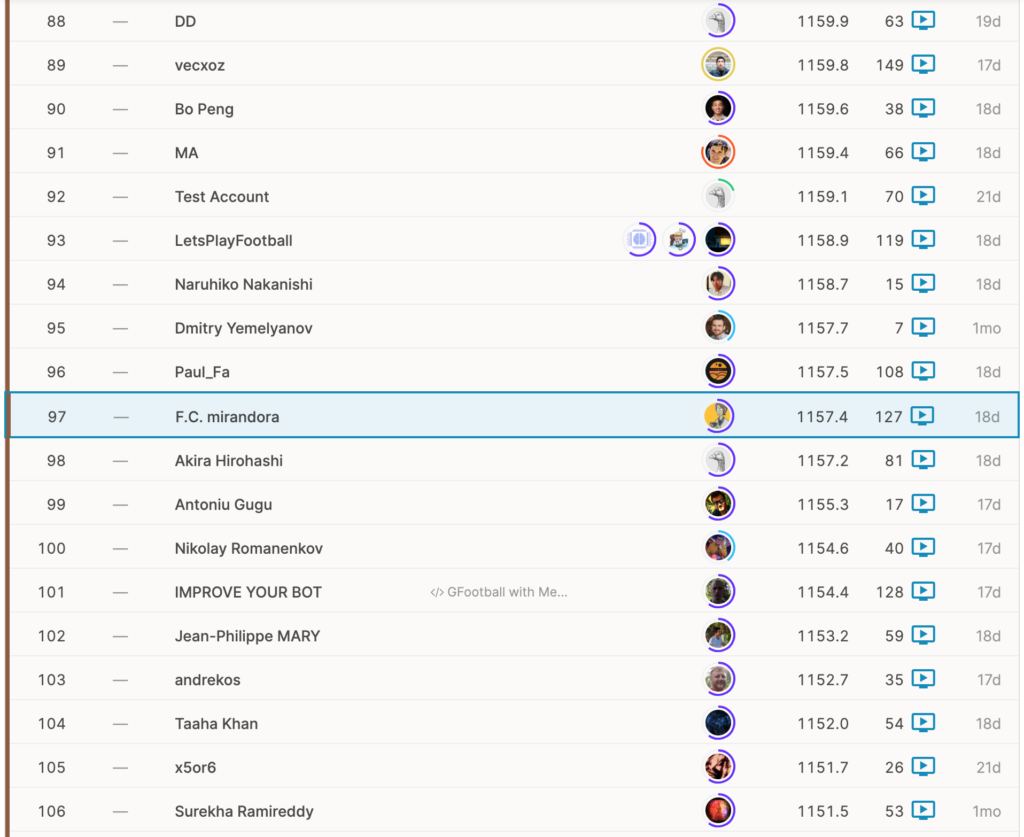
11月中旬くらいまではシルバー上位に位置しており、一時期金メダル圏内にもいたのですが、
1月中旬以降の他の参加者の追い上げに耐えきれず、ズルズルと順位を下げてしまいました。
反省としては、リプレイを見返して気になる点があったときにルールベースで対処してしまい、
機械学習ベースにかける時間が十分ではなかったように思われることです。
上位陣および上位解法
上位陣の方々は、すでに解法をKaggleのdiscussion上で公開しておりますので、
まずはその概要を見てみます。(解法discussionへのリンクも貼っておきます)
1位:強化学習 (WeKick: Temporary 1st place Solution)
2位:強化学習 (SaltyFish: Current 2nd place solution)
3位:強化学習 (Raw Beast 3rd place solution)
4位:不明 (現時点非公開)
5位:強化学習 (TamakEri: 5th place solution)
6位:強化学習 (Solutions of team “liveinparis” with codes (6th place))
7位:機械学習(模倣学習) (s_toppo: 7th Place Solution)
8位:不明 (現時点非公開)
9位:不明 (現時点非公開)
上記からわかる通り、上位陣はほぼ強化学習でした。
10位以下のメダル圏内の解法もいくつか公開されており、
ルールベース、機械学習(模倣学習)、ルールベース+機械学習がそれぞれあり、
今回のコンペはHaliteコンペのときよりもSimulationコンペとしての
データサイエンスとして取り組める幅は広かったように思います。
せっかくですので最後に1位の解法を紹介いたします。
1位解法
前述の通り、強化学習による自己対戦での方法となります。
Multi-player Online Battle Arena(複数プレイヤーでチームを組んで敵陣攻略を目指す「Honor of Kingsなどのゲーム」)での
強化学習論文として発表された、
“Mastering Complex Control in MOBA Games with Deep Reinforcement Learning”と似たフレームワークとのことです。
・ネットワークはいくつかの256次元のdenseレイヤーとLSTMブロックで構成
・学習はOpenAIのPPO(Proximal Policy Optimization、OpenAIが2017年に発表した方策勾配法の強化学習アルゴリズム)のベースラインを適用
・learning rateは1e-4で固定
・optimizerとしてAdamを使用
行動の価値推定の分散を減らすために、マルチヘッド値(MHV)を導入します(前述の論文でも同様の処置がで行われている)。
通常の強化学習ではゴールを報酬としたり、敵陣に攻めることを報酬にしたりしますが、
マルチヘッドにすることで、強化学習での報酬は、さまざまなヘッドに分解され、さまざまな割引係数で累積されます。
背後にある考え方は、一部のイベントは、インターセプト、オフサイド、スライドなどの最近のアクションとのみ高い相関関係がある一方で、
一部のイベントは、ゴールなど、より長い期間のアクションによって達成されるというものです。
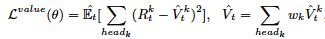
特徴量は、標準の115次元のパラメータに加えて、さらに下記を追加したようです。
・敵味方の相対的な位置(距離、角度)、つまり極座標
・自分がコントロールしているactiveプレイヤーとballの相対的な位置
・オフサイド位置のチームメイトのフラグ
・sticky action(移動などの慣性アクション)、各プレイヤーのイエローカード枚数、疲れ
また、報酬がまばらすぎるため、学習を効率的にスピードアップするために、
報酬をゼロサムにすることが非常に重要だったとのことです。
下記のような報酬を設計したようです。
・ボール奪取、アウトサイド、オフサイド:ゼロサム。+0.2(ボールポゼッションを獲得)、-0.2(ボールポゼッションを失う)
・スライディング:ゼロサム。+0.2(味方のスライディングが成功)、-0.2(敵のスライディングが成功)
・ボール保持:ゼロサム。+0.001(味方チームがボール保持を維持)、-0.001(敵チームがボール保持を維持)
・パス:+0.1(アシストパス)
上記のほか、モデルの多様性を持たせるために、
中央からの攻撃や別のモデルではサイドからの攻撃を奨励する報酬を設計したようです。
さらにモデルの堅牢性を高めるために、他プレイヤーのモデルを学習して、
それを対戦相手として固定して、学習したりもしたそうです。
例えば最終11位チームであった”kangaroo”というチームはカウンターアタックを中心とするチームで、
非常に参考になったとのことです。
モデルの多様性を持たせるために、「カウンターアタック志向のモデル」、「ショートパス主体のモデル」、
「ボール保持志向のモデル」などを独立して生成し、
互いに対戦してさらに精査していったようです。
通常のpublicLBでの結果は収束するまでに3日ほどかかるため、
正しくモデルを評価するためにローカルLBを作成し、
新しくモデルを作成した際は、ローカルLBで評価したようです。
強化学習はもとより、様々な点で自分が気づいていなかった点が多く、非常に勉強になりました。
次のSimulationコンペに参加する前に、ぜひ強化学習をものにしておこうと思いました。
(本で一通り学習したものの、実戦で使った経験無し…)
以上、footballコンペの振り返りでした。
Simulationコンペは通常のデータ分析コンペと異なり、
対戦相手のagentと戦った結果のポイントを競うものであることから、
同じレート帯、上位陣の名前やagentの癖は自然と覚えるもので、
コンペ終了後のdiscussionでも、他の対戦相手のプレイヤーへの感謝や敬意に溢れていることが印象的でした。
マリノスの今シーズンも終わり、自分自身の2020年の仕事納めも近づいておりますが、
今自分が仕事でやっていること(データサイエンス、というよりも企画色が強いかもしれません)の
“同じレート帯、上位陣”とは誰なんだろうか、
そして彼らに感謝や敬意を、と思いを馳せつつ、
今日もキーボードの傍ら、現実逃避にswitchのコントローラーを握る師走です。
関連記事:




人気記事: