Article

・Kaggleやデータ分析初学者向けのチュートリアル解説本を執筆しました。本記事とあわせてご参照くださいませ。
『Pythonで動かして学ぶ!Kaggleデータ分析入門』

・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
・その他のKaggle参戦記事一覧はメニューのKaggle挑戦記事からご参照くださいませ。
はじめに
本記事では2017年11月〜2018年2月に開催されておりました、Kaggleのmercariコンペの参戦振り返りをしていきます。ちなみに本コンペは私が初めてチュートリアルコンペ以外で参戦したKaggleのメダルありコンペでして、結果は236位/2381と悔しいものになったものの、ギリギリで上位10%でBronzeとはいえ初のメダル獲得ということもあり思い出深い経験になりました。その当たりの気持ちも思い出しながら振り返っていきたいと思います。
| (1) mercariコンペの概要
本コンペはKaggleで開催されたmercari提供のコンペとなります。mercariは日本最大級のフリマプラットフォームとなります。このコンペは、出品ごとの、出品タイトルや説明文、コンディション、カテゴリ、ブランドなどのデータが与えられ、それらの情報から各出品の落札価格を予想するという問題となります。予測モデルの精度は、RMSLE(Root Mean Squared Logarithmic Error:平均二乗対数誤差)によって評価されます。
余談ですがなぜ、mercariが落札価格を予測することが必要なのでしょうか。2つの理由が考えられます。1つは落札価格の予想から売上を予測すること、そしてもう1つは売上をより伸ばすためであると思われます。例えば落札価格を予測することができると”ユーザに適切な出品価格を知らせること”ができます。取引額の10%がmercariの取り分となることを考えると、それは重要なことです。取引成立、不成立のケース、それぞれで、もし適切な落札価格を予想して、mercariユーザに教えることができたら、mercariもユーザも、もっと儲かることができたケースが存在します。

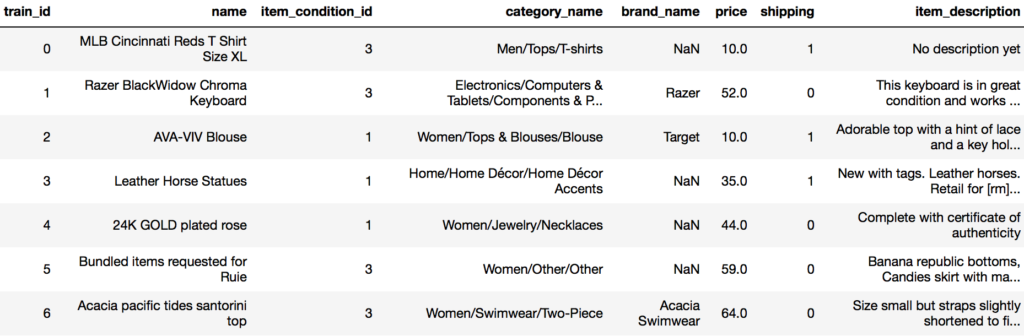
次にコンペで実際に提供されたデータの項目、およびデータ量を見ていきます。
train_data(学習データ:1,482,535データ)
test_data(落札価格を予測するテストデータ:693,359データ)
| id | 商品ID |
| price | 商品の落札価格(今回、test_dataで予想すべき値。test dataには存在せず) |
| name | 商品名 |
| item_condition_id | 商品の状態(5段階評価) |
| category_name | 商品カテゴリ |
| brand_name | 商品ブランド名 |
| shipping | 送料を出品者が払うか落札者が払うか |
| item_description | 商品詳細 |
これらの値は、出品するユーザが記載するものであることに留意です。
※つまり誤字脱字やブランクなどもあり得る)実際のレコードは下記のようなものとなります。
このコンペは、2stage制のCode Competitionとなります。
・データ解析(プログラムの実行)は、オンライン上のカーネルで行う
・2stageコンペとなり、stage1では、公開されたtrain data/test dataを用いてモデルを作成する
・stage2では、非公開の別のtest dataが適用され、最終的な順位が決定される
・カーネルの実行時間は60分以内であること
本コンペは他のコンペと比較してカーネル実行時間制限が大変厳しく、予測精度を高めるだけではなく高速に動かすためのエンジニアリング能力が求められました。 ※「Kaggleは、あなたのプログラムの処理を12時間も待つことも、コンペの終了を先延ばすこともしたくない。」とコンペの説明ページに記載されておりました。
| (2) 本コンペへの取り組み
本コンペに取り組むに当たり(正確に言うと取り組みながら)、やはり実行時間の壁が大きく、通常のデータ分析フローに加えて特に下記を意識しました。
・与えられたデータのうち、name、category,item_descriptionの項目がテキストデータであり、これらをいかに(実行時間内に高速に)処理するか
・制限時間内に予測を終えるためにどのようなモデルを用いるか
まずは今回の目的変数である落札価格に関して簡単にEDAを行いました。train dataでの落札価格の分布は下記のようになります。
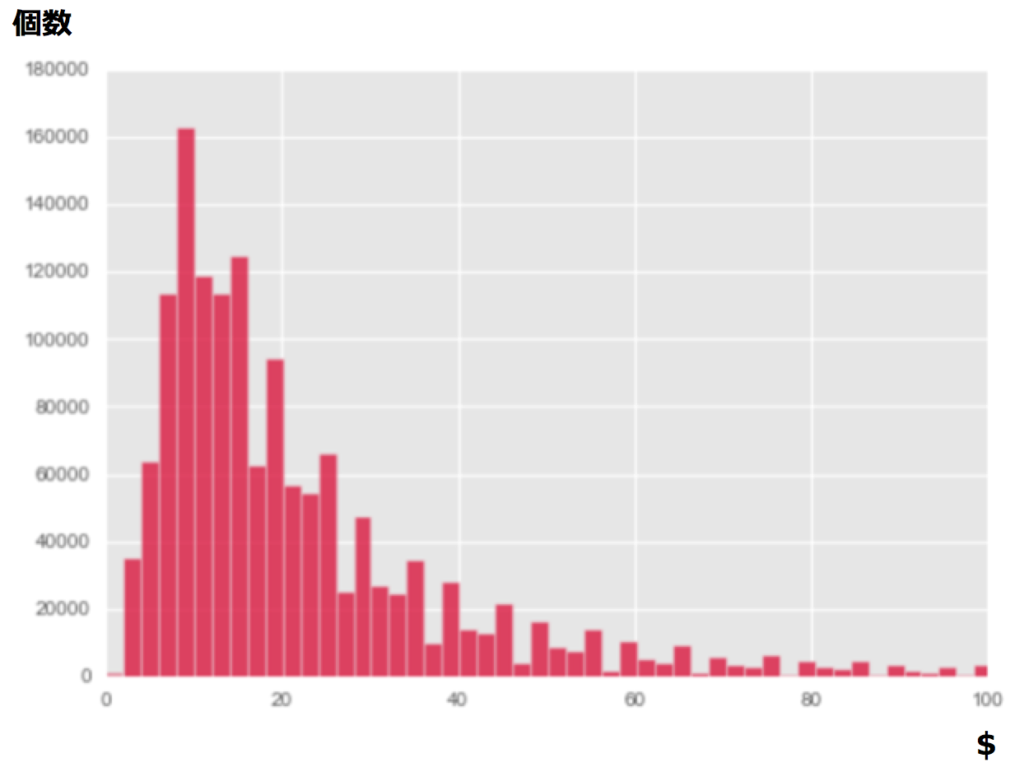
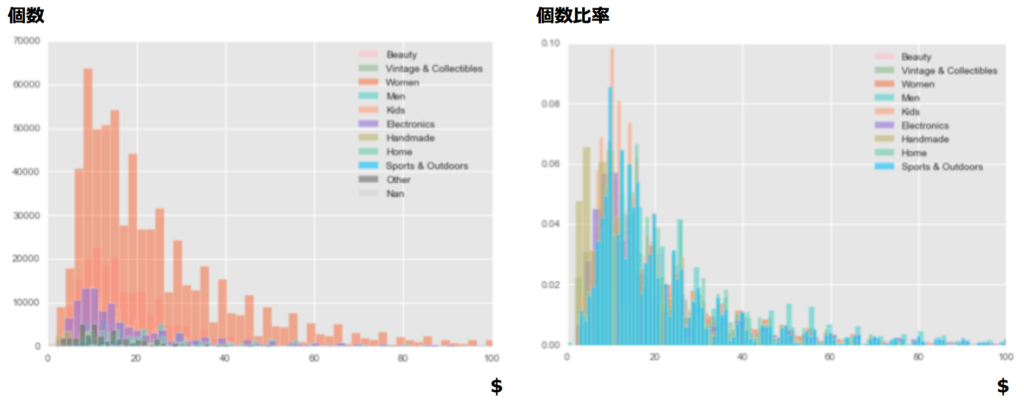
また各カテゴリごとの価格の平均値・中央値・最小値・最大値は下記となります。
| カテゴリ名 | 平均($) | 中央値($) | 最小値($) | 最大値($) |
| Beauty | $20 | $15 | $0 | $2,000 |
| Electronics | $35 | $15 | $0 | $1,909 |
| Handmade | $18 | $12 | $0 | $1,750 |
| Home | $25 | $18 | $0 | $848 |
| Kids | $21 | $14 | $0 | $809 |
| Men | $35 | $21 | $0 | $1,309 |
| Nan | $25 | $16 | $0 | $1,000 |
| Other | $21 | $14 | $0 | $1,400 |
| Sports & Outdoors | $26 | $16 | $0 | $915 |
| Vintage & Collectibles | $27 | $16 | $0 | $1,709 |
| Women | $29 | $19 | $0 | $2,009 |
上記から「価格の分布は低価格帯に集中していること」、「各カテゴリの最低価格が(なぜか)$0となっていること」がわかり、まずは下記の前処理を行うことにしました。
・train dataを落札価格が$0より上のものに絞る
・予測する目的変数を対数変換
次にデータ中の欠損値を確認したところ、category_nameが6,314(全体の0.4%)、brand_nameが632,336(全体の42.7%)が欠損していることがわかりました。そこで特にbrand_nameについてはタイトルや説明文から補完する処理を実装しました。
※ただし、”All”や”Complete”などの一般用語ブランド名は 補完対象から除外。
さらに「item_descriptionがしっかりしているものは、同じ商品でも高い落札価格になっている」という考え、説明文の長さを変数に加えました。
 name、item_descriptionは形態素解析し、tfidfや各単語出現頻度を変数化しそれらをlightGBMでモデリングするあたりをベースラインとしました。このあたりでPublic Scoreで0.5あたりであったと思います。ここからさらにitem_descriptionにおける誤字脱字の修正の前処理や記号使用頻度などの特徴量を加え、lightGBMで0.47876、XgBoostで0.46545、アンサンブルで0.46059となりました。しかしこの時点ではまだ順位はPublic LeaderBoardでちょうど真ん中あたりで上位半数にも入れていませんでした。
name、item_descriptionは形態素解析し、tfidfや各単語出現頻度を変数化しそれらをlightGBMでモデリングするあたりをベースラインとしました。このあたりでPublic Scoreで0.5あたりであったと思います。ここからさらにitem_descriptionにおける誤字脱字の修正の前処理や記号使用頻度などの特徴量を加え、lightGBMで0.47876、XgBoostで0.46545、アンサンブルで0.46059となりました。しかしこの時点ではまだ順位はPublic LeaderBoardでちょうど真ん中あたりで上位半数にも入れていませんでした。
| (3) 苦労した点・結果
ここからさらに様々な特徴量を増やしたり別のアプローチを模索していました。たとえばよく似たitem_descriptionがいくつか見られるのですが、これは同じ人が類似商品を出品しているときに見られるようで、item_descriptionの類似しているものの近傍平均を特徴量に加えるなどです。
しかし結果的には上記は断念しました。処理時間制限60分の壁です。その時点でおおよそ下記のような状況でした。
| タスク | カーネル上での処理時間(分) |
| パッケージ・データ・モデルインポート | 2 |
| その時点での前処理 | 10 |
| 予測時間 | 40 |
| 予測結果のアンサンブルから提出ファイル作成 | 1 |
前処理はまだもう少しやりようがありそうだと思い、高速にするためにリファクタリングした上でいくつかの処理を追加、その上でここまでモデリングをlightGBMとXgboost中心で進めてきたものの、より高速に動作するridge回帰や1d-cnnを試すようにしました。特に1d-cnnは高速なベースラインコードが公開カーネルがアップされたことにより多くの人が試したのではないかと思います。この時点で単体で0.4600まで精度を上げることができ、さらに1d-cnnをいくつかの隠れ層のバリエーションをつけてアンサンブルしたことで精度がかなり上がり、最終的にPublic:0.4290/Private:0.43005、上位10%でBronzeとなりました。
当時周囲にKaggleをやっている知人がおらずチュートリアルコンペを触ったあと、初めてのメダルつきコンペでBronzeの意味合いがよくわかっていませんでしたが、メダルを獲得できたことは単純に嬉しさがありつつ実力不足を痛感しました。(※後日談となりますが、このコンペから次のKaggleコンペ本格参戦まで時間が空くことと、久しぶりに参戦したいくつかのコンペではshake downしてしまい、ここから次のメダル獲得まで想定より間が空いてしまいました。)
おおよそのスコアの推移は下記となります(縦軸:各時点での最高予測精度(rmsle)、横軸:submit no)。初期のsubはそもそもcode competitionに慣れておらずerrorが多く、0.5あたりになったあたりでようやくベースラインがまともに動くようになりました。終盤はなかなかPublic scoreが上がらず手詰まりになる一方、他の参加者が凄まじい勢いでスコアを上げていくことに焦った記憶があります。
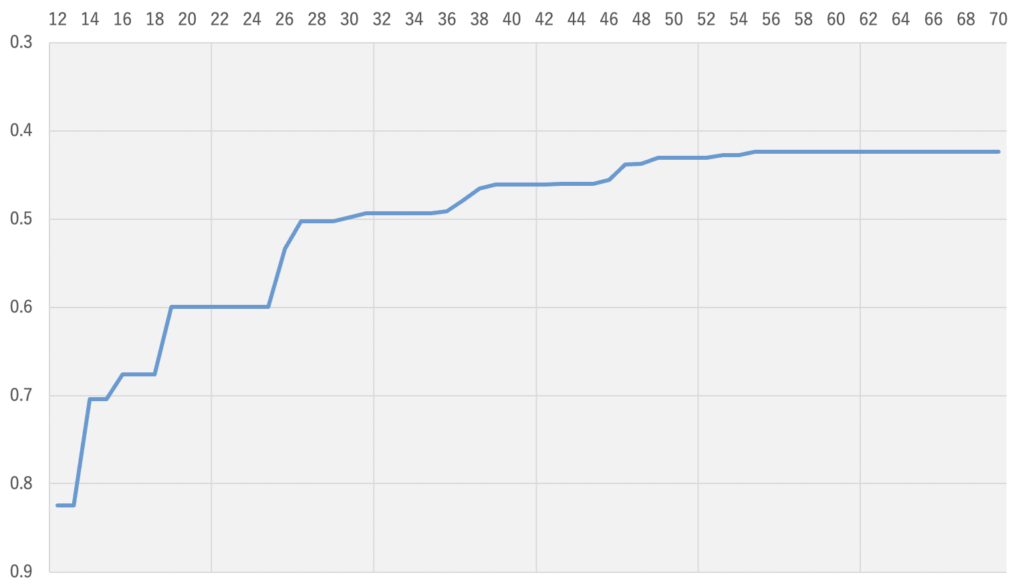 自然言語処理において今回のような100万行以上のデータを前処理やその後のモデルの予測含め全処理60分以内というシビアな制約の中高速に処理するという経験・ノウハウが不足していたことが大きな敗因だったと思います。また1d-cnnは中盤以降大きく精度を伸ばすことができましたが、これに関しても自分の中で様々なパターンでのベースラインコードや実験手順を整理しておきたいと痛感しました。
自然言語処理において今回のような100万行以上のデータを前処理やその後のモデルの予測含め全処理60分以内というシビアな制約の中高速に処理するという経験・ノウハウが不足していたことが大きな敗因だったと思います。また1d-cnnは中盤以降大きく精度を伸ばすことができましたが、これに関しても自分の中で様々なパターンでのベースラインコードや実験手順を整理しておきたいと痛感しました。| (4) 上位解法
1位のソリューションは概要とベースコードが共有されています。ポイントは下記となります。
・いくつかの前処理のパターンによりデータのバリエーションを増やす。モデルの多様性よりデータの多様性を重視
・前処理の高速化のために、複数のテキスト列をまとめる。(”name”、”brand_name”を1つに、”item_description”、”name”、”category_name”を1つに)
・上記のまとめたテキスト列およびいくつかの特徴量をtfidfでsparse matrixに。その際、make_unionを用いて処理を並列化
・上記のsparse matrixをbool化したものを元のデータに繋げる
・予測は1d-cnn。3epoch学習するがepochごとにbatch_sizeを2倍にして高速化しつつ過学習を避ける。
・予測対象を64のクラスにbin、クラス分類としてソフトに解くことをアンサンブルに加える。
・予測との残差を目的変数にしたモデルをアンサンブルに加える。
ベースコードは非常に簡潔にまとまっているものの、上記のうち1つめの前処理は特に何もしなくても(また最後のクラス分類のアンサンブルを加えなくても)単体データ/モデルでrmsleが0.38まで到達できます。これは前処理に苦労していた自分にとって衝撃でした。コードでも非常に参考になる点があり、コンペ終了後に1位のみでもコードや解法を見ながら再現実験をすることが重要だと痛感しました。
| (5) 余談
後日談となりますが、本コンペ中はまだ公開されていなかったものの近年、自然言語処理ではBERTを使うことが多いと思います。たとえばnameやitem_descriptionをBERTによるアウトプットvectorを特徴量としたり、item_descriptionのBERTを用いたポジネガ判定なども特徴量に追加するなども考えられます。しかしそれらを追加実験したところ、今回のデータ量ではとても60分以内の処理に収めることができないどころか、結局1位のtfidfでのsparse matrixを用いた1d-cnnのほうが精度が高い結果となりました。今後、自分がNLPコンペあるいはテーブルデータにテキストデータが含まれるコンペに参加する際にBERTではないアプローチとして心に留めておきたいと思った次第です。
以上、mercariコンペの振り返りでした。
関連記事:




人気記事: