Article
今回はamazonの購入履歴を取得する方法について見ていきます。
2014年11月現在、”amazon.com”については管理画面から、購入履歴のデータをダウンロードできるようですが、
“amazon.co.jp”はローデータでの購入履歴の取得はできません。(なぜなのでしょうか、。)
本稿では、Ruby[ref]実行時に、”Syntax error”となる場合は、プログラムの改行コードが”LF(LINUX)”となっているかチェックです。[/ref]を用いてWebスクレイピングする方法について見ていきます。
だいたい最近の言語ですと、Webスクレイピング用の外部ライブラリが用意されておりますが、
Rubyの場合は”Nokogiri”および”Mechanize”となります。[ref]ネーミングについては、Pythonの”BeautifulSoup”の方が、かっこいいですね、。[/ref]
Nokogiri、Mechanizeのインストール、詳細については“Nokogiri の基本(翻訳版)が詳しいです。
以下は、すでにNokogiri、Mechanizeがインストールされているruby環境で進めてまいります。
といっても、ターミナルで以下を入力すればインストールできるかと思います。
|
1 2 |
gem nokogiri install gem mechanize install |
まずはプラグインを設定したあと、mechanizeでagentを立ち上げて、好きなUserAgentを設定します。
|
1 2 3 4 5 6 7 8 |
require 'open-uri' require 'nokogiri' require 'mechanize' require 'csv' require 'kconv' agent = Mechanize.new agent.user_agent_alias = 'Windows IE 7' |
その後、amazonのログインページにアクセスし、ログインします。
|
1 2 3 4 5 6 |
url = 'https://www.amazon.co.jp/ap/signin?_encoding=UTF8&openid.assoc_handle=jpflex&openid.claimed_id=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.identity=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.mode=checkid_setup&openid.ns=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0&openid.ns.pape=http%3A%2F%2Fspecs.openid.net%2Fextensions%2Fpape%2F1.0&openid.pape.max_auth_age=0&openid.return_to=https%3A%2F%2Fwww.amazon.co.jp%2Fgp%2Fyourstore%2Fhome%3Fie%3DUTF8%26ref_%3Dnav_signin' page = agent.get(url) login_form = page.forms_with(:name => 'signIn').first login_form.fields_with(:name => 'email').first.value = "アカウントのメルアド" login_form.fields_with(:name => 'password').first.value = "パスワード" page2 = login_form.click_button |
無事ログイン出来ているかは、取得ページのタイトルが、
「注文履歴を見る」になっているか、確認するとよいかと思います。
|
1 |
puts page2.title |
さて、ここからが本題のamazonの注文履歴のスクレイピングとなりますが、
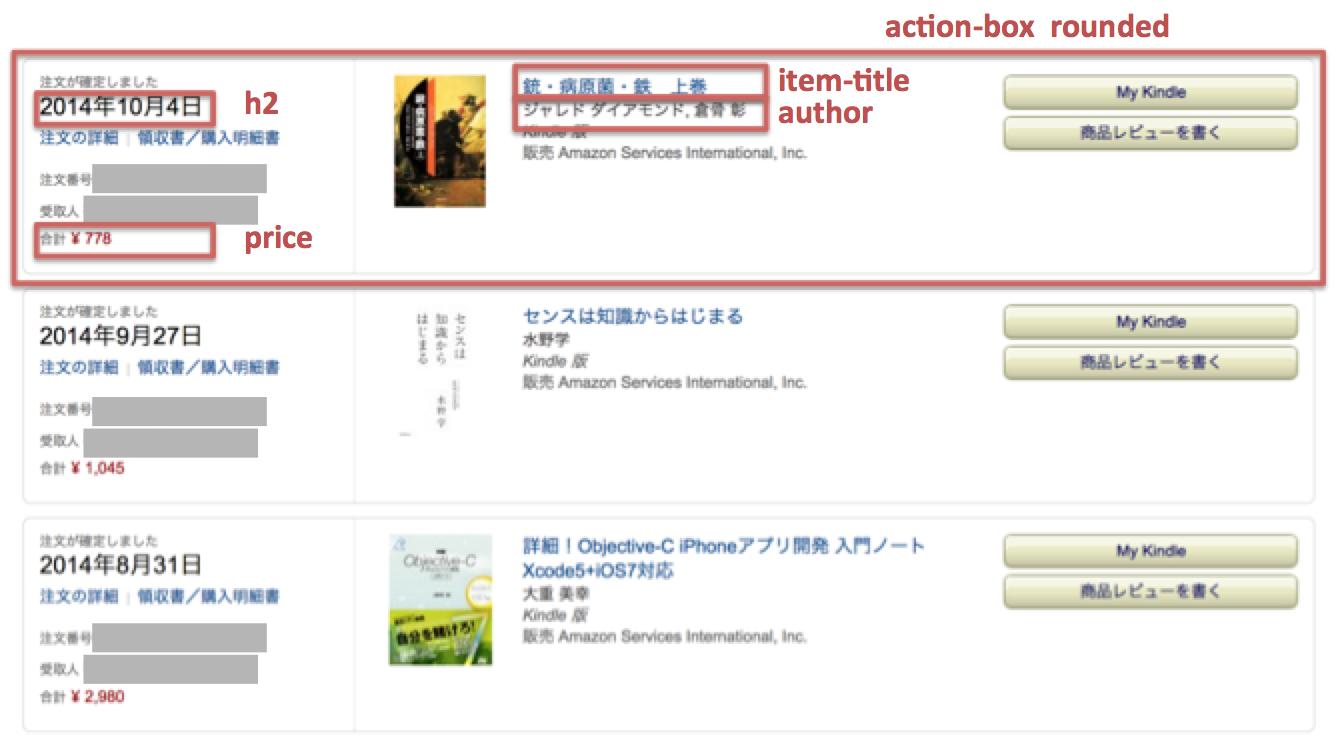
amazon注文履歴のcssは2014年時点では下記のようになっています。

なぜ、日時のh2要素のみ、class、id指定が無いのでしょうね、。
h2要素は、「配達を完了しました」「予約注文済み」などの購入ステータスにも用いられているため、
何らかの方法で除去する必要があります。
上記のcssのnameをたよりに、”action-box rounded”ごとに処理をしていけば抽出できます。
日時のh2箇所(ステータスコードの除去)の処理はかなり強引ですが、。
処理は以下の手順となります。
(1) 自動でcsv書き出ししたいので、csvを開いて、表頭を記入
(2) 集計年ごとにURLを開く
(3) Nokogiriにかます。
(4) “action-box rounded(注文履歴)”が空かチェック
(5) 空でなければ、順次csvに記入
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
his_year =2014 #任意の集計開始年 during =3 #任意の集計年数(この場合、2014年から3年) CSV.open('amazon.csv','wb') do |csv| csv << ['date','title','author','price'] for year_count in 0..during do for num in 0..10 do url = "https://www.amazon.co.jp/gp/css/order-history/ref=oss_pagination_top_#{(num)}_#{(num+1)}?ie=UTF8&orderFilter=year-#{his_year-year_count}&search=&startIndex=#{num*10}" page = agent.get(url) html =Nokogiri::HTML(page.body,nil,'Shift-JIS') if html.css('span.item-title').text.length == 0 then break else puts url html.search('//div[@class="action-box rounded"]').each_with_index.map do |box,i| #chompは改行を削除するmethod #stripは先頭や末尾の空白を削除 #gsubは文字列を置換する。 #tosjisは文字コードを変換 date = box.css('h2').text.chomp.strip.gsub("配達を完了しました"," ").gsub("予約注文済み"," ").tosjis title = box.css('span.item-title').text.chomp.strip.tosjis author = box.css('div.author').text.chomp.strip.tosjis price = box.css('span.price').text.chomp.strip.tosjis csv << [date,title,author,price] end end end end end |
これにて、csvでamazonの注文履歴を下記のように書き出すことが可能です。

ちなみに上記では記述を省略していますが、実際に実行する際は、sleepなどを用いて、
連続アクセスでamazonに迷惑がかからにようにご注意くださいませ。。
なお、上記と同様の方法をPythonのBeautifulSoup、
あるいは、VBAを用いる方法などを用いることでも可能かと思います。
どの言語を用いるかはプログラマの好みによるところかと思います。
以上、今回はRubyを用いたamazon.co.jpからの購入履歴の取得方法についてみていきました。
関連記事:





人気記事: