Article

今回はブログの書き込みデータを取得する方法を見ていきます。
今回、ブログデータの中でも”書き込み日時”、”記事タイトル”、”記事内容”を特に見ていきますが、
ブログサービスによって、その他付随している”タグ”や”コメント数”などの情報も
以下の方法で同様に取得可能かと思います。
今回、ブログデータを取得するために、Rubyの”Anemone”パッケージを使用します。
「Amazonの購入履歴を取得する」で見たように、
Rubyのmechanize+nokogiriでもよいのですが、
Anemoneには再帰読み込みなど、クローリングに便利な機能がもともとついておりますので
コードがスッキリするかと思います。
※といっても、情報の抜き出しにはnokogiriを用います。
anemone自体のインストールは別の記述に譲りますが、下記で可能かと思います。
※事前に必要なパッケージなどはお使いの環境にあわせてください。
※”権限が無い”というエラーが出る場合は「sudo gem〜」で実行してください。
|
1 |
gem install anemone |
まずは必要なパッケージをロードします。
|
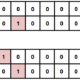
1 2 3 4 5 |
# -*- coding:utf-8 -*- require 'anemone' require 'nokogiri' require 'kconv' require 'csv' |
続いて、対象となるURLを設定し、
anemoneに再帰呼び出しさせます。
|
1 2 |
urls = ["http://tacumi.jugem.jp/"] Anemone.crawl(urls,:depth_limit => 1) do |anemone| |
ちなみにループ対象となるページを絞りたい場合は
上記ループ中の中でさらに、正規表現で、特定の文字列を含むサブドメインなどを
指定するとよいかと思います。
|
1 |
anemone.on_pages_like(%r[month=\d+]) do |page| |
あとは、ブログの抜き出したい箇所に応じて、
正規表現で抜き出すか、あるいはdiv中のものであればnokogiriに処理させるのも手かと思います。
以下は、日時やタイトルがdivできれいに囲まれていないときに、
特定の文字列で正規表現で抜き出す例です。
|
1 2 |
date = page.body.toutf8.scan(%r!<font size=2 face=verdana color=black>(.+?)</font>!) title = page.body.toutf8.scan(%r! <font face="ms pgothic" size=2>(.+?)<p>!) |
上記で一通りの処理となるのですが、いくつか細かい点について補足します。
(1) メタ文字のエスケープ
正規表現などで文字列を抜き出そうとした際に、メタ文字と呼ばれる特殊な記号が含まれている場合、
エスケープ処理をする必要があります。
メタ文字のエスケープについては下記、様々なサイトでまとめていただいておりますので、ご参照ください。
http://www.rubylife.jp/regexp/ini/index5.html
http://www.mk-mode.com/octopress/2013/02/13/regexp-html-tag/
(2) 文字のエンコード
続いて、文字の処理をしていると1度はつまづくのが、文字のエンコードとなります。
anemone、nokogiriなどで抜き出してきた文章について、何も考えずに処理すると、
対外、「Encoding::UndefinedConversionError」や「Encoding::InvalidByteSequenceError」に
出くわすことになります。
適宜、文字コードを指定する、前処理として未定義の文字を置き換える、必要があります。
文字コードについては下記詳しくまとめられております。
http://ref.xaio.jp/ruby/classes/string/encode
(1),(2)をふまえ、たとえばブログ本文が、特定のdivで抜き出せないとき、
さらに大きな固まりでdiv指定して取得し、エスケープ処理しながら邪魔な文字列(タグ含む)は削除していきつつ、
文字コードを正しく指定することで、必要なブログ本文を得ることができます。
|
1 2 3 4 |
this_article = articles[num].text.chomp.strip.gsub(/<(".*?"|'.*?'|[^'"])*?>/, "") this_article2 = this_article.gsub(/ \"(.+?)> | \- /m,"") this_article3 = this_article2.gsub(/function(.+?)important/m,"") this_article4 = this_article3.encode(Encoding::SJIS, :invalid => :replace, :undef => :replace) |
以上で、適宜csvに書き出せば自動でブログの内容一覧を取得することが可能です。
得られたデータは、MeCabなどで、形態素解析や共起語分析などすると、
意外な発見があって面白いかと思います。
※たとえば、下記は友人のブログを自動で収集し、RMeCabで共起語分析した例となります。

このままでは、細かいノイズが多くて、何がなんだかよくわかりませんね笑
共起語分析をRMeCabで処理する際に、きれいに表示するための方法については、
別記事で書いてみようと思います。
以上、今回はブログデータの取得でした。
関連記事:



人気記事: