Article

社会人とは、時にどうしても立食パーティー的なものに出席せざるを得ないことがあります。
近況報告や業界情報を語り合う人々の波を抜け、壁際でスマホをいじっている人物、それが私です。
ニュースアプリとメールを2,3周読み直しても、どうしても時間を持て余す時、
苦虫を噛んだような顔でfacebookを開くことになるでしょう。
さて、facebookのタイムラインを眺めていると、あることに気づきます。
社交的な人のプロフィール画像と、
非社交的な人のプロフィール画像は、様子が異なる、ということです。
現代において、SNSのプロフィール画像とは、本人の顔以上に、友人と接する機会が多いものになり得ます。
ゆえに、プロフィール画像、それは、本人の、SNS、ひいては交友関係、ひいては自分自身に対する意識が表れやすいものになります。
きらびやかな海を背景にビール片手に満面の笑みでサムズアップしている写真(トリミングされているが友人が横にいる気配を感じる)を
プロフィール画像にするプログラマがいないのと同様、
暗めの仕事場らしき場所でタイピング中のうつむき気味の横顔(深めにかぶった帽子などで巧妙に目を隠す)を
プロフィール画像にするパーティーピープルがいないことは周知の事実です。(偏見)
そこで前置きが長くなりましたが、本稿では、
私のfacebookの友人の、「友達の数」と「プロフィール画像」をpythonで機械学習し、
「友達の数ごとのプロフィール画像傾向」を解析してみたいと思います。
| (1) facebookデータの収集
facebookでの自分を起点としたデータは、facebook Graph APIから取得することができます。
集計は、developersページ内のfacebook Graph APIエクスプローラから
FQL(Facebook Query Language)という、SQLライクな言語を用いることができます。
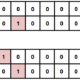
たとえば、Facebook内の、自分の友達の、名前、友達の数、プロフィール画像を取得するには
一般のSQL同様、下記の通りとなります。
※2016年6月現在、FQLではJOINを用いることはできないようです。
|
1 2 3 |
SELECT name,friend_count,pic_big FROM user WHERE uid IN (SELECT uid2 FROM friend WHERE uid1 = me() ) |
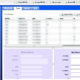
結果は下記のようになります。
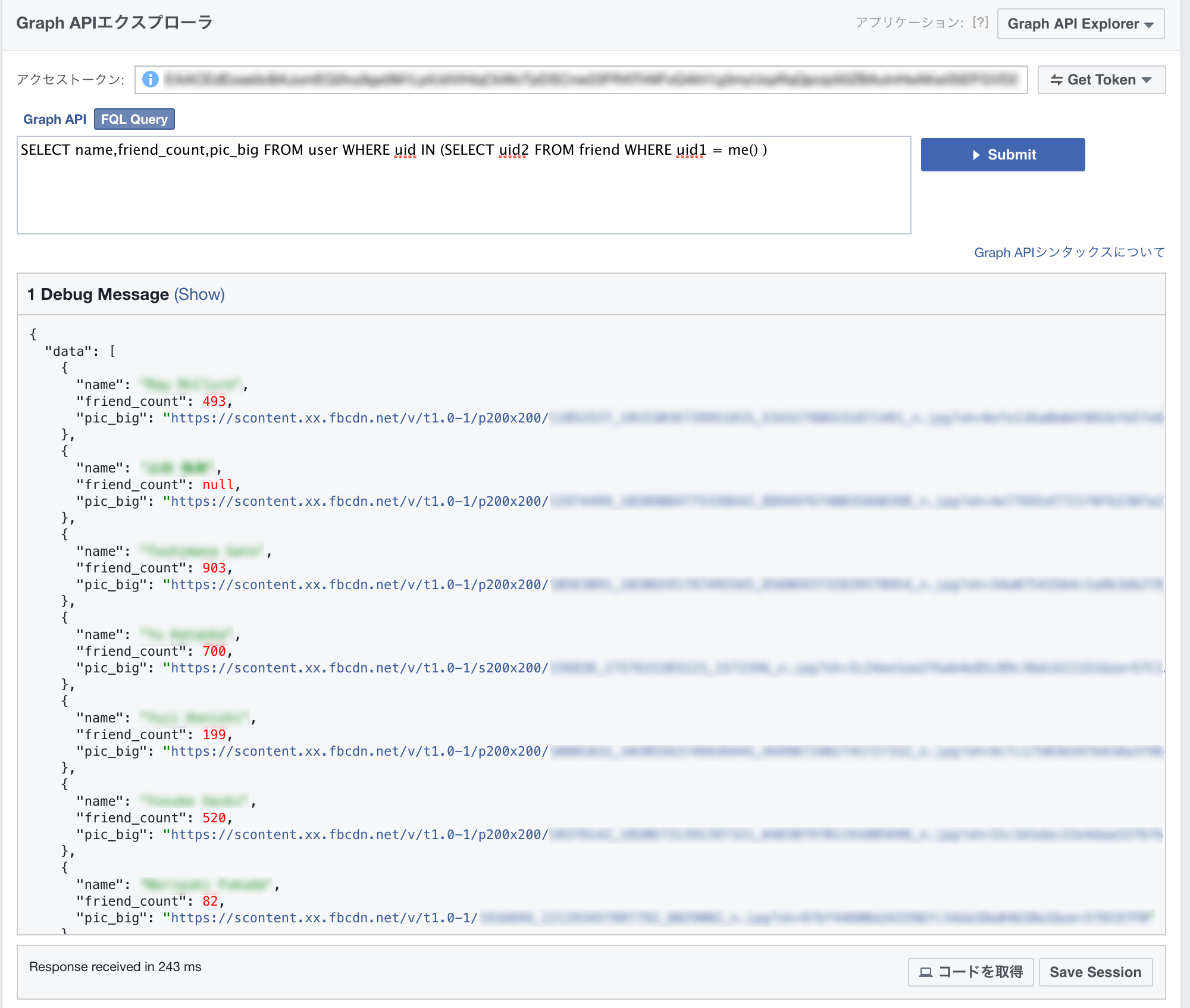
ただし、ここで1つ注意です。
Graph APIは1.0までは上記のFQLですべての友達のデータを取得できていたのですが、
2.0になってからfacebookアプリ承認済みの友達の一部データのみが取得できるようになりました。
おそらく多くの人にとって、上記で取得できるデータは一部の友達のみのデータとなると思います。
よって、各々得意な方法でスクレイピングする必要があります。
| (2) 分析に用いたデータの概要
今回、私のfacebookから取得した、プロフィール画像付き友達データの概要は下記の通りとなります。
※今回はプロフィール画像を登録していない友達、および友達数を非公表の友達、は
分析データから除外いたしました。
※本データは、あくまで本稿のみの分析に使用しております。(さもないと、ただでさえ少ない私の友達が減ることでしょう。)
| データ数 | 346 |
| 友達の平均友達数 | 685 |
| 友達の最大友達数 | 3,839 |
| 友達の最小友達数 | 4 |

ちなみにRのggplot2でヒストグラムを書くには下記の通りとなります。
※Rにインポートするデータ名をfacebook、友達の友達数がfriends_numという項目とする。
※alphaは描画する透明度ですので任意。binwidthがヒストグラムでまとめるデータ幅となります。
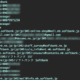
|
1 2 3 4 5 |
library(reshape2) library(ggplo2) g<-ggplot(facebook,aes(x=friends_num)) g<-g+geom_histgram(alpha=0.5,binwidth=100) plot(g) |
(友達数が非公開の友達を分析対象外としたという前提があるにせよ)
私自身の友達数が346であることと比較し、
私の友達の友達の平均数は685と2倍近いようです。
いつもみなさまの社交性に助けられているようで、この時点で非常に申し訳ない気持ちになりました。
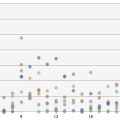
友達が1,000人以内の友達が多数ですが、1,000人以上の友達を持つ友達も少なからずいるようです。
1,200人あたりが境目でしょうか。
ではいよいよプロフィール画像を分析していきましょう。
| (3) プロフィール画像の分析
まずは全友達のプロフィール画像の平均を見てみることにしましょう。
本稿では、友達の平均顔を作成することが目的ではなく、
どのようなプロフィール画像を用いているかを知ることが目的となります。
つまり、もし自分の顔写真をプロフィールにしているとしたら、
顔をどのくらいの大きさで写しているのか、どのような構図で自分が写っているのか、
といったことに興味があります。
よって画像ごとの顔の位置合わせはしません。
(そもそも人物ではない画像をプロフィールにしている友達もいるため)
平均画像は単純に考えれば各画像ベクトルをそのまま足し上げて画像数で割ればよいですが、
画像数が増えるとメモリを一気に消費することになります。
そこで画像処理では主成分分析によって次元を削減することが常套手段となります。
facebookのプロフィール画像を分析する際の注意点としては、
プロフィール画像のサイズが均一ではないということです。
私がスクレイピングした結果では多くの画像は200×200で得られましたが、
一部画像はもっと小さいサイズとなりました。(原画像のサイズによる?)
pythonでの画像処理の際に「setting an array element with a sequence.」エラーが出たようなら、
画像のリサイズが必要となります。
pythonを用いて平均画像を作成した結果が下記となります。
※形状に興味があるため、グレー画像に変換して計算しております。
※コードは長くなってしまったため整理して追って追記予定
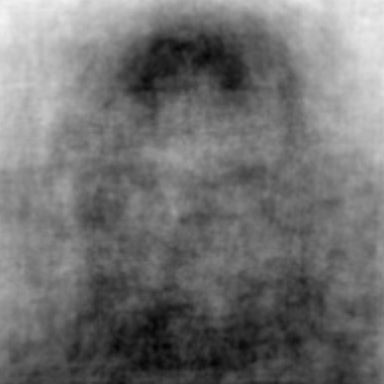
全体平均画像からは、正面での顔のアップ、といったスタンダードな印象を感じます。(そういった画像が多い?)
ちなみに下記が主成分分析の結果となります。
※左から第一主成分、第二主成分、第三主成分
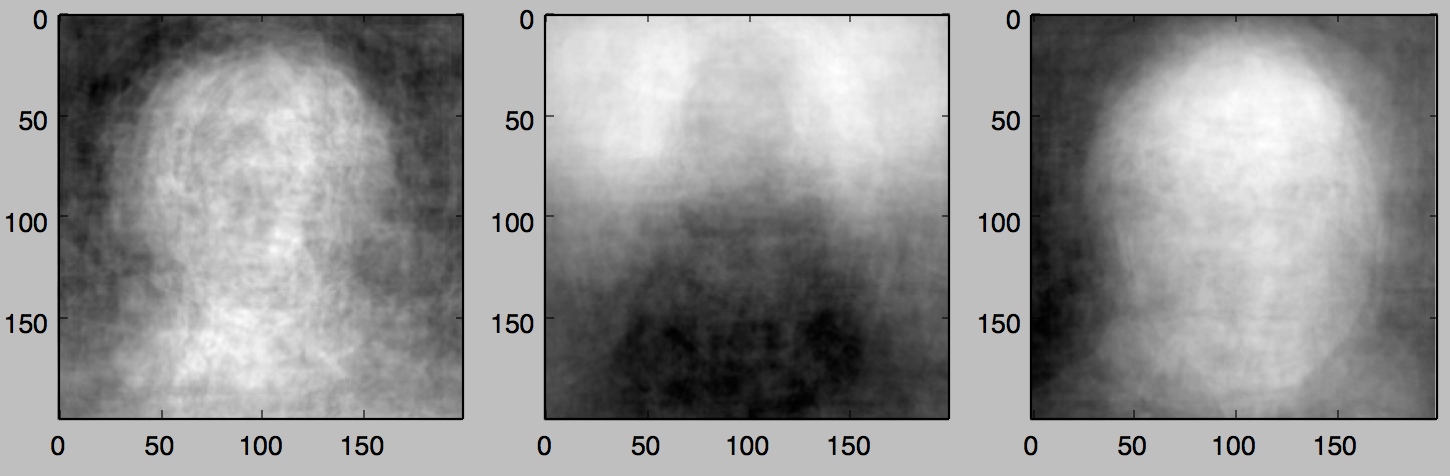
実は、上記のようなプロフィール画像をそのまま用いて主成分分析からのクラスタ分析を行ってもうまくいきません。
画像が細かすぎて、ささいな違いに引っ張られてしまうのです。
もっとざっくりとしたパターン(アップなのかヒキの画像なのか、どういうポーズなのか、など)で分類したほうが直感と合います。
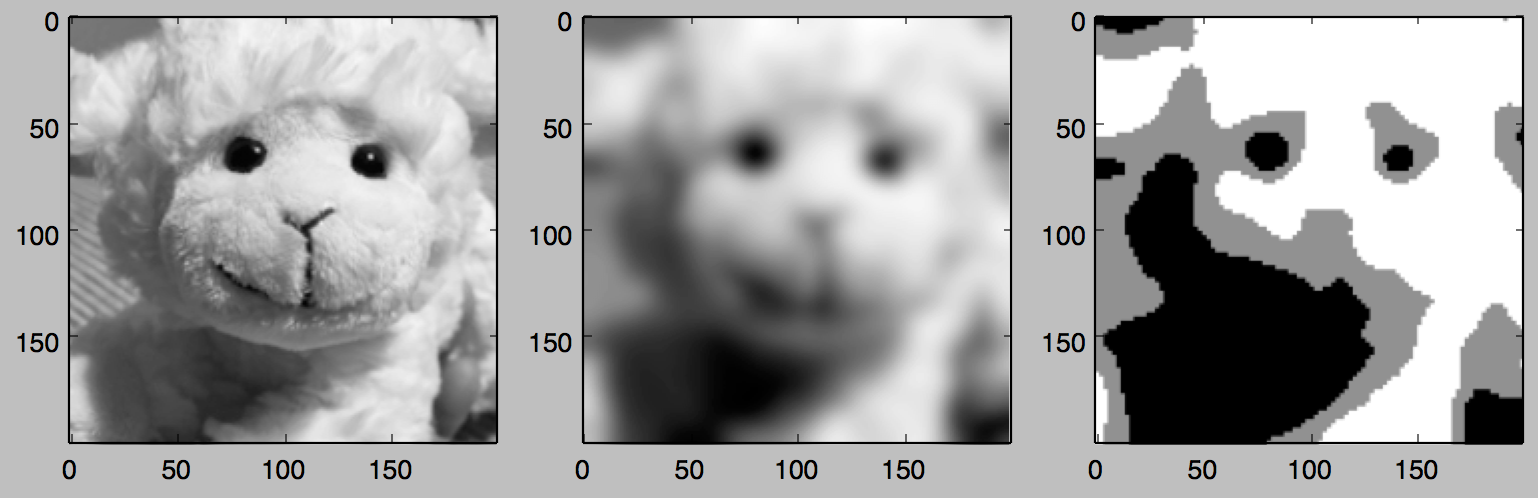
そこで原画像をぼかした上で、さらに低解像度な粒度(今回は100×100領域で、白・黒・グレーの3段階の値)に落とす前処理をすることにします。
※下記は、私の家にあったヌイグルミ写真での前処理イメージ
1.ぼかし処理を入れずに低解像度処理をした場合
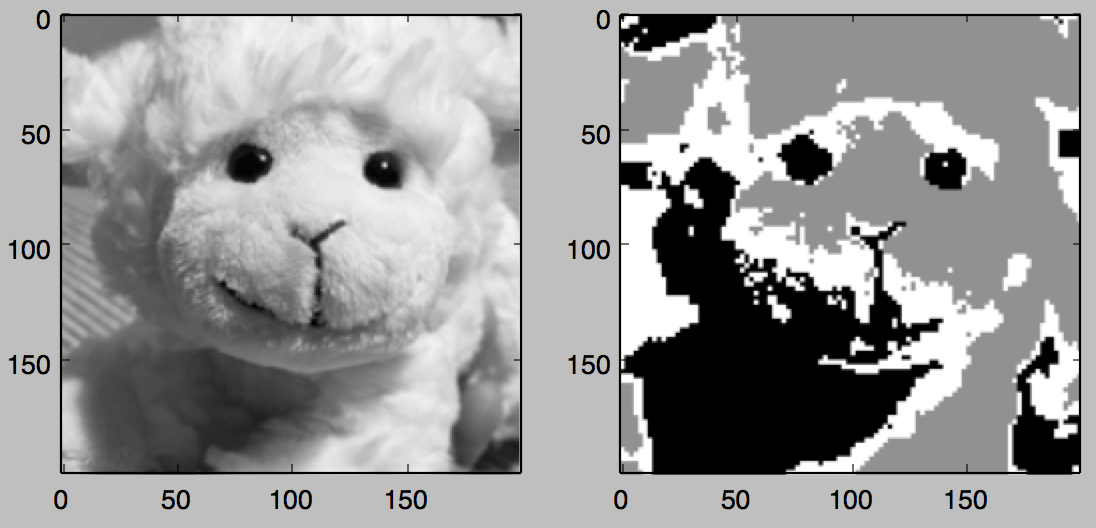
2.ぼかし処理を入れたのち、低解像度処理をした場合(今回採用した前処理)
さて、ではここからはクラスタ分析により類似画像にグループ分けし、
各クラスタごとの平均友達数に違いがあるか、を見ていきましょう。
今回はシンプルにk-meansで分類してみます。
前処理後の平均画像
前処理後の主成分分析(左から第一主成分、第二主成分、第三主成分)
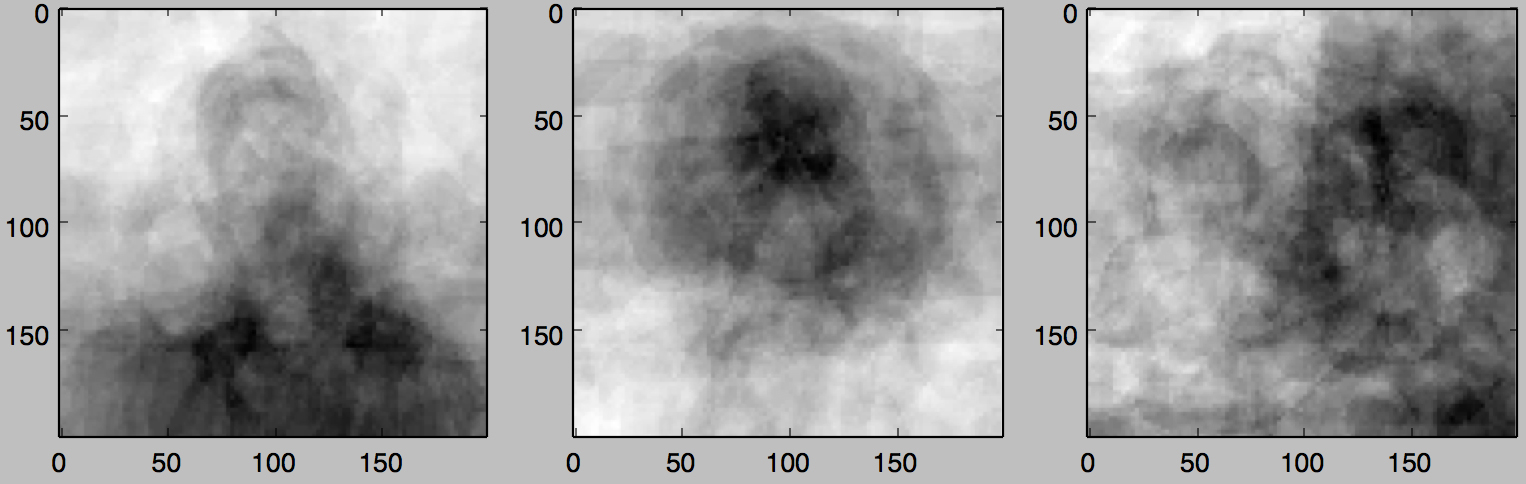
上記主成分分析の結果をもとにk-meansクラスタリングで5クラスタに分類した結果が下記となります。
プロフィール画像からの類似画像のクラスタ分析
| クラスタ | n | 平均友達数 |
| クラスタ1 | 74 | 565 |
| クラスタ2 | 86 | 825 |
| クラスタ3 | 42 | 607 |
| クラスタ4 | 79 | 720 |
| クラスタ5 | 65 | 643 |
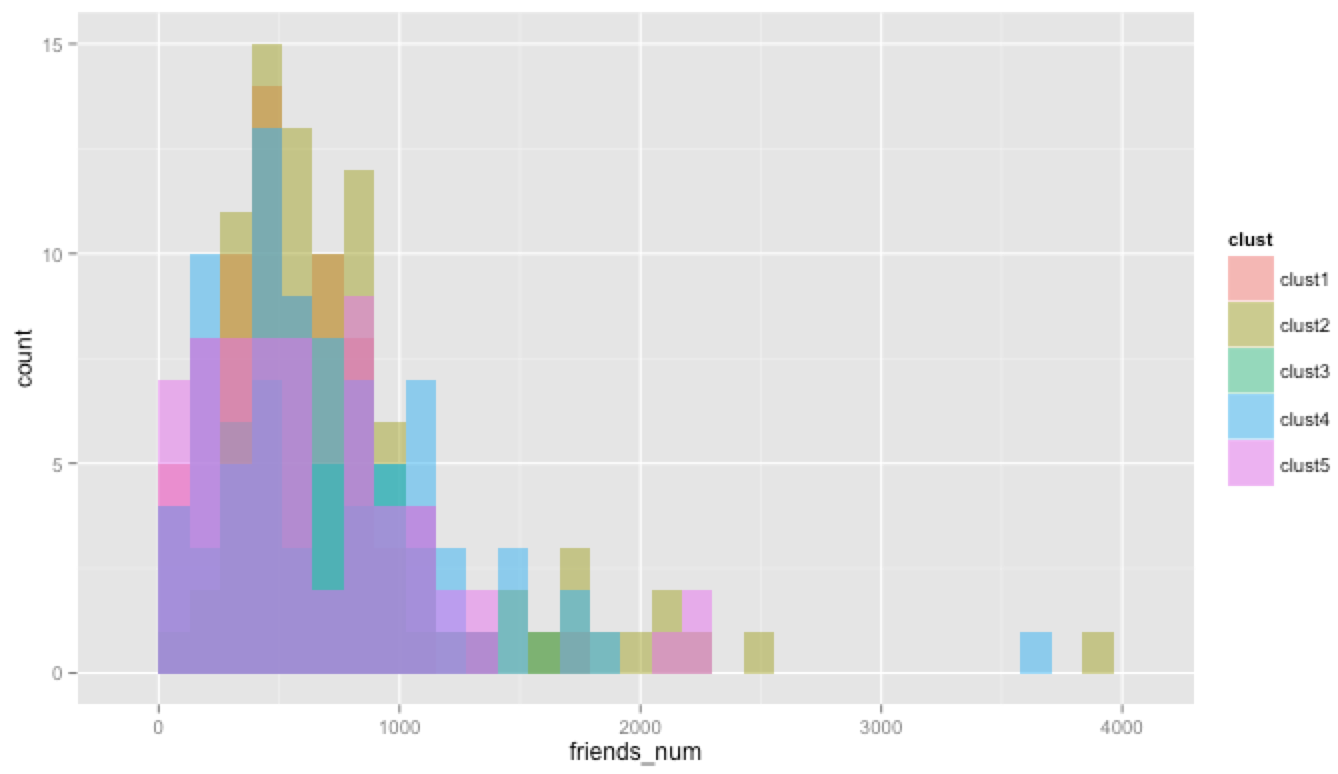
友達数の分布がクラスタごとに散らばることを期待したのですが、
どのクラスタもピークおよび分布は、似ているように見えます。
※本来、各クラスタの分類結果ごとのプロフィール画像をお見せできると非常にわかりやすいのですが、
前述の通り、伏せさせていただきます。
さて、とはいえ、クラスタ2に分類されたプロフィール画像を設定している人たちが友達数が多いようです。
これは一体どのようなプロフィール画像を設定している人たちなのでしょうか。
彼らの平均画像が下記となります。

上記だけだと分かりづらいのですが、分類結果に含まれている画像をみると、おおよそ下記のパターンとなります。
(1) 基本的にイラストなどではなく、顔が写っているバストアップの写真。
(2) 正面ではなく、やや斜め。
(3) オシャレなカフェらしき場所がさりげなく背景に。
いかがでしたでしょうか。
みなさま、ぜひ、”やや斜め”に写った写真を使用しましょう。
最後に私がかれこれ10年以上使用しているSNSでのプロフィール画像を載せておきます。

こちらは、私が鉛筆で描いたイラストにパソコンで色つけしたものです。
何故このような画像をずっと使用しているかは私自身にも正直理解しかねますが、
しかし、もちろん変える予定はありません。
ええ、人誰しもが、多くの友達を求めているわけではないということです。
関連記事:



人気記事: