Article
今回はtwitterのデータを用いた分析のために、
twitterからのローデータの取得に必要な手順を書いていきます。
まず、はじめにtwitterからのローデータ取得については、
2013年3月に大きな変更がありました。
以前は、URL指定(RSS、XML、Atomなどで)で、
特定のアカウントの、つぶやきデータを取得することが可能でした。
そのため、cgiなどで都度URL経由で任意のアカウントのつぶやきを取得してきて、
ビジュアライズするといったことが容易に可能でした。
しかし、2013年3月以降、
API経由、もしくはダウンロードデータでの分析が必須となり、
上記URL指定でのつぶやき取得は廃止されました。
※追記:apiの更新の詳細、廃止時期の延期情報などは以下で確認できます。
https://dev.twitter.com/blog/api-v1-retirement-final-dates
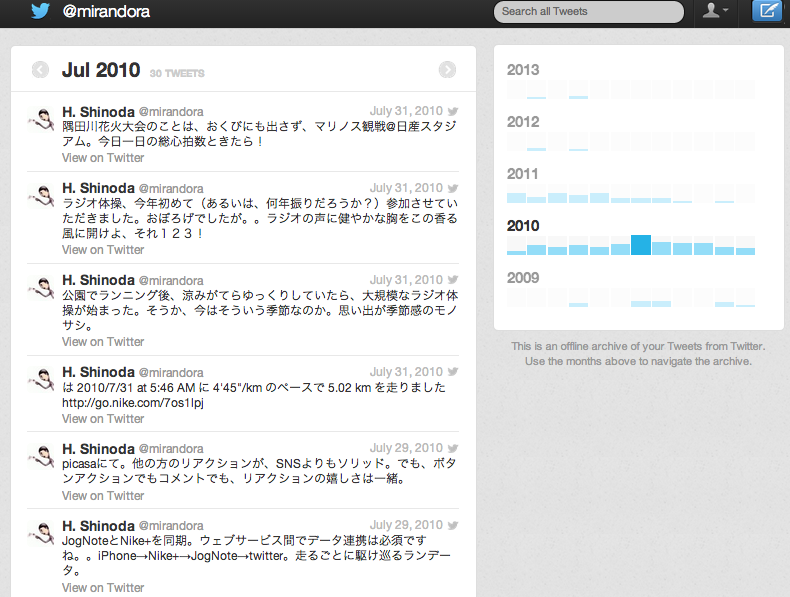
今回は、主に自分のアカウントのつぶやきをダウンロードし、
ビジュアライズするまでのフローについて見ていきます。
具体的には以下2つの手順となります。
(1) データの取得
(2) データの整理、調整(時間補正、日本語変換)
(1) データの取得
まずは自分のtwitterアカウント画面からつぶやきデータのダウンロードを行います。
※今後更新される可能性がありますが、
現時点で、英語アカウントからの順次提供のようです。
※そのため、全てのアカウントでデータ取得が可能かは不明です。
もし日本語アカウントで以下フローが行えない場合、
念のため英語の設定に変えてみてください。
「アカウント設定画面」を下にスクロールしていくと、
「Request your archive」ボタンがありますので、クリックします。
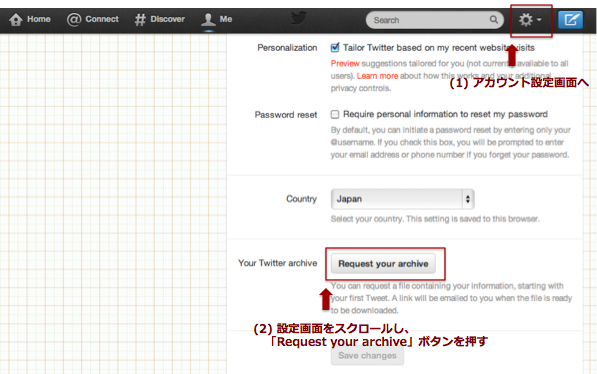
すると、受領およびすぐにデータがメールで送付される旨、表示されます。
早ければ1、2分でメールが届きます。
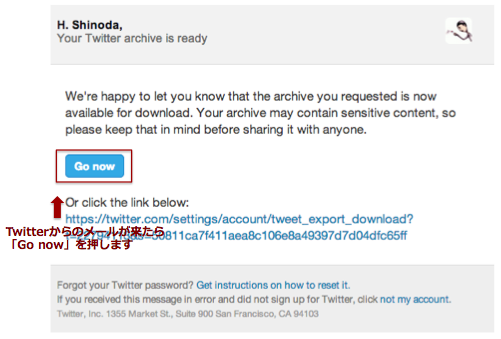
twitterからメールが送付されたら、本文中の「Go now」を押すと、
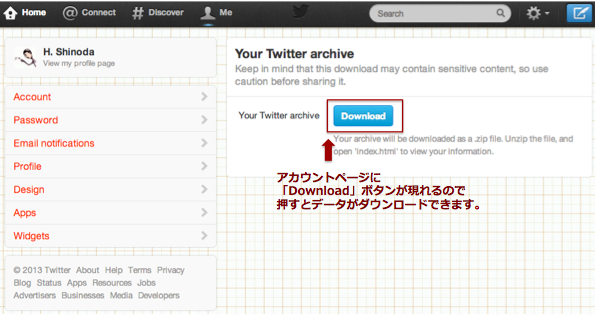
アカウント画面にリンクしますので、そこから「Download」を押しましょう。
「tweets.zip」というファイルが取得できます。
以上で、データの取得は完了です。
(2) データの整理、調整(時間補正、日本語変換)
まずはデータを確認してみましょう。
ダウンロードした「tweet.zip」の中身は以下の構成となっています。
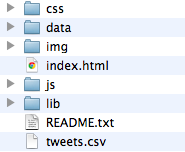
その中から、まずは「index.html」をクリックしてみましょう。
ダウンロードしたデータを、任意の指定した区間で確認できます。

次に、データ加工のためのローデータを確認します。
データ加工のためのローデータは
フォルダトップにある「tweets.csv」あるいは、
「data」→「js」→「tweets」にある、任意の区間のjsファイルとなります。
※jsファイルをもとにデータを取得する際は、
文字がエンコード文字となっていることに注意してください。
任意の方法でデコードする必要があります。
(文字のデコードの方法は今回は長くなりますので省略します。)
上記のデータの中から今回、分析に必要な箇所のみ(時刻、つぶやき)
をデータから抜き出して整理しましょう。
時刻は、年月日、曜日、を分けておくと便利かと思います。
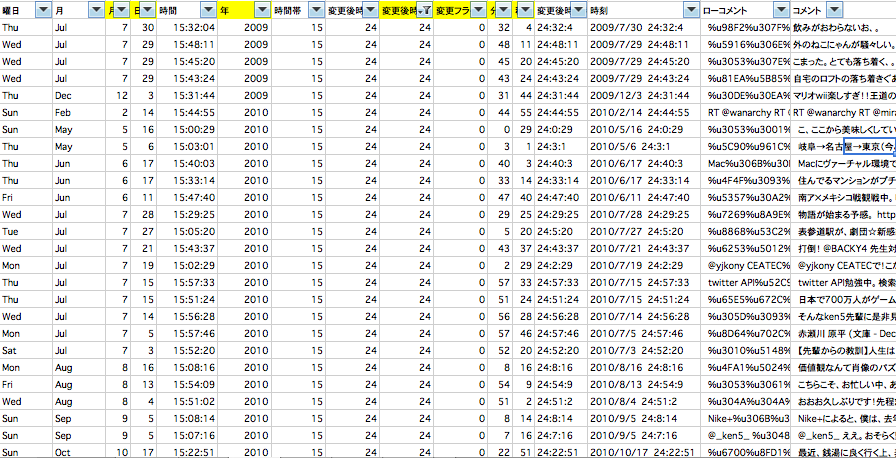
その際に、時刻の修正をします。
ローデータのファイルは協定世界時となっているため、
JST(日本標準時)にするには9時間進める必要があります。
※実際、ローデータと自分のつぶやきの時刻に
9時間のずれがあることを確認してみてください。
※今後、日本語アカウント対応になれば、デフォルトJSTとなる可能性もあります。
上記でtwitterのローデータの取得および、ビジュアライズの準備が出来たかと思います。
あとは、任意の方法でビジュアライズしてみてください。
例:twitterのつぶやきを円形に表示する。

関連記事:




人気記事: